Unlock the potential of machine learning models by leveraging trial and error methods to achieve optimal performance and accuracy.
Understanding the Concept of Trial and Error in Machine Learning
Trial and error is a fundamental concept in machine learning that involves iteratively testing different approaches and refining the model based on the observed outcomes. It is a powerful technique for optimizing machine learning models as it allows us to learn from mistakes and make incremental improvements.
By embracing trial and error, we can explore a wide range of possibilities and identify the best strategies for model development. This iterative process helps us understand the strengths and weaknesses of different approaches, enabling us to make informed decisions and achieve superior performance. Trial and error also encourages creativity and innovation, as it allows us to think outside the box and discover novel solutions to complex problems.
Moreover, individuals unfamiliar with machine learning can still engage in diverse experiments with varying configurations. Despite lacking expertise in optimizing complex AI models, they have the opportunity to conduct a range of experiments. This inclusivity is crucial for democratizing technology and making it accessible to a broader audience unfamiliar with its intricacies. And the mission of Deep Block and Omnis Labs is to increase the accessibility of artificial intelligence technology even to those who do not know AI technology.
Determining the Ideal Image Resolution for AI Image Analysis in DeepBlock.net
In the field of AI image analysis, determining the ideal image resolution is crucial for achieving accurate results.
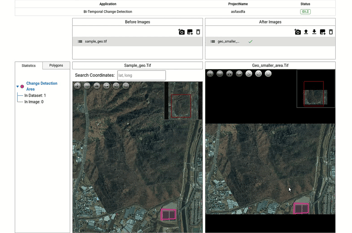
In particular, high-resolution images must be divided and analyzed. Please refer to our company's resource page for numerous issues related to this.

For this purpose, Deep Block provides an interface to divide and analyze HIGH-resolution images. Check out the powerful performance of this ability through the following video.
The project we utilized can be accessed at this page.
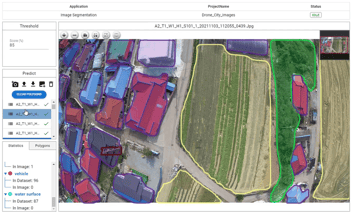
Experimenting with various image resolutions can lead to finding the ideal unit image resolution. Since machine learning models simply resize high-resolution image files, it is essential to divide large image files for accurate analysis.
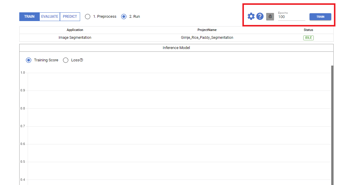
Another approach is to experiment with different epoch settings. Deep Block offers a project duplication feature and access to a scalable GPU cloud online for this purpose. Users can train models with varying epochs simultaneously, assess model performance, and determine the optimal training epoch. For a detailed explanation and video demonstration, please refer to the following link.
By leveraging trial and error, we can explore different image resolutions and evaluate their impact on the performance of our AI image analysis models in DeepBlock.net. Experiment can help us in finding the optimal unit resolution, ensuring that our models achieve high accuracy. This iterative approach allows us to refine our models and adapt to diverse image analysis tasks.
Exploring Different Techniques for Optimizing Machine Learning Models
Optimizing machine learning models involves exploring various techniques and strategies to improve their performance and efficiency.
Some common techniques for optimizing machine learning models include early stopping and image splitting. By leveraging trial and error, we can systematically test and evaluate these techniques to identify the most effective ones for our specific problem.
Implementing Trial and Error Strategies in Model Development
Implementing trial and error strategies in model development allows us to systematically explore different approaches and make incremental improvements. By embracing this iterative process, we can fine-tune our models and achieve better performance.
One effective strategy is to start with a simple model and gradually introduce complexity while monitoring its performance. This approach allows us to understand the impact of different model components and make informed decisions about their inclusion. Additionally, trial and error can help us identify and address potential issues such as overfitting or data imbalance.
By continuously testing and refining our models through trial and error, we can optimize their performance and ensure they are well-suited for the intended task. This iterative approach is key to achieving state-of-the-art results in machine learning.