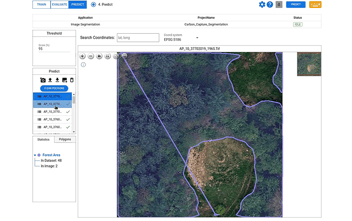
The sheer volume and complexity of geospatial data make it challenging to analyze and extract meaningful insights. This is where machine learning comes in. Machine learning algorithms can be trained to recognize patterns in geospatial data and provide real-time predictions based on those patterns. The combination of geospatial data and machine learning enables us to make informed decisions in real time.
Geospatial technology is the use of location data to solve problems and answer questions. It encompasses everything from GPS tracking and satellite imagery to geocoding and spatial analysis. Geospatial data can come from a variety of sources, including satellites, drones, ground-based sensors, and other devices. Machine Learning Operations (MLOps), however, is the practice of automating machine learning workflows, from data preparation to deployment.
Geospatial MLOps is the intersection of these two fields, combining geospatial technology with MLOps to improve the accuracy and efficiency of location-based models, transforming the way that many organizations approach geospatial data analysis. By automating the process of analyzing, processing, and visualizing location data, analysts can streamline the identification of patterns, trends, and anomalies in geospatial data, providing a level of accuracy and insight that was previously impossible.
The integration of geospatial data analysis and machine learning operations is not a new concept. However, the term Geospatial MLOps has gained popularity in recent years due to its relevance in many areas. Its flexibility and customizability make it a powerful tool that enables data scientists, engineers and GIS specialists to process and analyze large volumes of geospatial data, which ultimately helps provide situational awareness and support decision-making.
In sum, Geospatial MLOps helps organizations deploy cutting-edge computer vision models. Such technology is gaining increasing traction for a growing range of use cases in Environmental Monitoring, Urban Planning and Smart Cities, Agriculture and Precision Farming, Natural Resource Management, Disaster Management and Emergency Response, Infrastructure Management, Energy and Utilities, as well as Geospatial Intelligence and Defense.
1. The History of Geospatial MLOps.
Geospatial MLOps has a rich history that dates back several decades. The roots of Geospatial MLOps can be traced back to the early days of geospatial analysis, when manual interpretation of aerial photographs and maps was the primary method of extracting information from geospatial data. This labor-intensive process relied on the expertise of skilled analysts who would manually identify and annotate features of interest.
The emergence of machine learning techniques revolutionized geospatial analysis by automating the process of feature extraction and classification. In the late 1990s and early 2000s, what would later become Geospatial MLOps started gaining traction as researchers and practitioners realized the potential of integrating machine learning with geospatial data. One notable application was in remote sensing, where machine learning algorithms were used to classify land cover types based on satellite imagery. This opened up new possibilities for land use planning, environmental monitoring, and resource management.
The introduction of deep learning, a subfield of machine learning that utilizes artificial neural networks with multiple layers, brought about a significant breakthrough in Geospatial MLOps. Convolutional neural networks (CNNs) became the go-to architecture for tasks such as image classification, object detection, and image segmentation, enabling more accurate and robust geospatial analysis.
As Geospatial MLOps progressed, the integration of multi-modal data became a key focus. By combining different types of geospatial data, such as satellite imagery, aerial photographs, LiDAR, and radar data, practitioners were able to gain a more comprehensive understanding of the Earth's surface. This fusion of data sources provides valuable insights for applications such as urban planning, disaster response, and precision agriculture.
Advancements in Geospatial MLOps have been accelerated by collaboration between academia, industry, and the open-source community. Open-source tools and no-code platforms by startups like Deep Block have played a pivotal role in promoting knowledge sharing, experimentation, and innovation in the field, making Geospatial MLOps more accessible to a wider audience.
2. Understanding the Geospatial MLOps Workflow.
Geospatial MLOps involves a series of processes that enable the training and deployment of machine learning (ML) models for geospatial analysis in defense applications. The Geospatial MLOps workflow can be divided into several key steps. Each of these steps must be carefully planned to endure the model’s robustness, performance, and longevity:
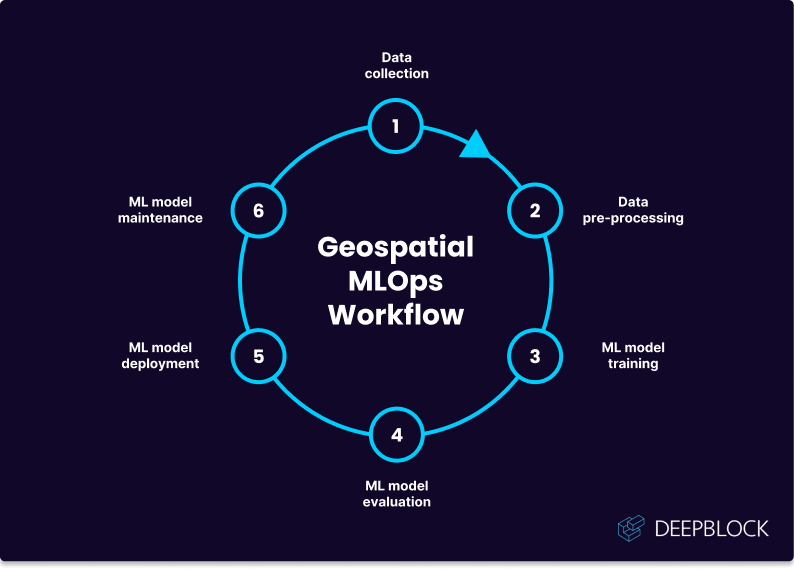
- Data collection: Geospatial data can come from various sources, including satellites, drones, and other sensors. Data collection can involve a range of tools and technologies, including data processing pipelines and cloud-based storage solutions.
- Data pre-processing: The data needs to be cleaned and pre-processed to ensure that it is in a format that can be used for ML training. This step can involve the use of data cleaning tools, data normalization techniques, and data augmentation methods.
- ML model training: This step involves selecting the appropriate ML algorithms and training the model on the pre-processed data. The use of synthetic data can help to address the challenge of representative training data. Model development can involve a range of ML algorithms, including deep learning, decision trees, and support vector machines.
- Model evaluation: The performance of the ML model needs to be evaluated to ensure that it is accurate and reliable. This step can involve the use of performance metrics, such as precision, recall, and F1 score.
- Model deployment: This step involves deploying the ML model into a production environment. This can involve the use of containerization and microservices to enable scalability and flexibility. The deployment of the model needs to be closely monitored to ensure that it is performing as expected.
- Model maintenance: The ML model needs to be updated and maintained to ensure that it continues to perform effectively. This step can involve the use of monitoring and feedback loops to ensure that the system is performing as expected.
3. Data collection for Geospatial MLOps.
Geospatial data collection forms the foundation of geospatial MLOps, providing the raw material for analysis and decision-making. By harnessing a diverse array of sources, including satellites, drones, aerial platforms, CCTV systems, and ground-based sensors, organizations can capture valuable spatial information and unlock insights that drive innovation across various domains.
Satellite Imagery: A Bird's Eye View of the Earth.
Satellite imagery is a cornerstone of geospatial data collection. Earth observation satellites orbiting the planet capture high-resolution images across the electromagnetic spectrum. These images provide a bird's eye view of the Earth's surface, enabling analysis and monitoring at regional, national, and global scales. Satellite imagery offers several advantages, including:
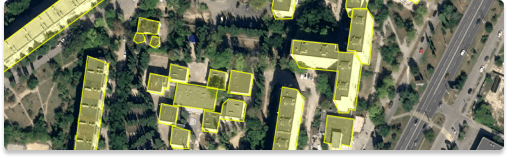
- Large-Scale Coverage: Satellites can capture vast areas of land, making them ideal for monitoring land cover changes, urban growth, deforestation, and agriculture over broad regions.
- Temporal Analysis: By acquiring regular satellite imagery over time, organizations can analyze temporal changes, identify trends, and monitor dynamic processes such as vegetation growth, water bodies' fluctuations, and urban sprawl.
- Multispectral and Hyperspectral Capabilities: Satellites equipped with multispectral and hyperspectral sensors capture data across different spectral bands. These bands correspond to specific wavelengths of light, allowing for the detection and differentiation of various land cover types, vegetation health, soil moisture, and more.
Drones and Aerial Platforms: Capturing Fine-Grained Details.
Drones and aerial platforms offer the ability to capture geospatial data at a more localized and detailed level. Equipped with high-resolution cameras, LiDAR sensors, and other specialized instruments, drones provide an agile and cost-effective solution for capturing geospatial data. Some benefits of drone and aerial data collection include:

- High Resolution: Drones can capture images and LiDAR point clouds at a significantly higher spatial resolution compared to satellite imagery. This enables detailed analysis of smaller areas, such as infrastructure inspection, land surveying, and environmental monitoring at a local scale.
- Rapid Deployment: Drones can be deployed quickly, allowing for timely data acquisition in response to specific events or emergencies. They provide flexibility in capturing geospatial data for real-time monitoring, disaster response, and situational awareness.
- 3D Mapping: LiDAR sensors mounted on drones capture point cloud data, enabling the creation of highly accurate 3D models of the Earth's surface. This technology finds applications in topographic mapping, urban planning, and infrastructure modeling.
CCTV Systems: Extracting Insights from Urban Environments.
CCTV systems, commonly deployed in urban areas for surveillance and security purposes, can also serve as a valuable source of geospatial data. By integrating computer vision techniques with geospatial analysis, CCTV data can be leveraged to extract valuable insights. Some benefits of using CCTV systems for geospatial data collection include:

- Human Activity Monitoring: CCTV footage allows for the tracking and analysis of human movement patterns, vehicle traffic, and crowd behavior. This information can support urban planning, transportation optimization, and public safety initiatives.
- Anomaly Detection: Computer vision algorithms applied to CCTV data can identify and flag abnormal events or behaviors in real-time, such as traffic accidents, unauthorized access, or suspicious activities. This aids in proactive decision-making and incident response.
Geospatial MLOps relies on a plethora of imaging technologies to capture data about the Earth's surface, unveiling a rich tapestry of information that fuels analysis and decision-making. These cutting-edge imaging technologies encompass a range of remote sensing modalities, each offering unique advantages and unlocking new dimensions of spatial understanding.
Electro-Optical Sensors: Picturing the Visible and Beyond.
Electro-optical sensors play a pivotal role in geospatial data collection, capturing imagery using visible light and near-infrared radiation. These sensors, mounted on satellites, aircraft, and drones, offer a multitude of benefits:

- High-resolution imagery: Electro-optical sensors capture images with exceptional detail, providing high-resolution imagery that allows for the identification and analysis of small-scale features on the Earth's surface. This enables the detection of individual objects, such as buildings or trees, and precise land cover classification.
- Multispectral capabilities: Electro-optical sensors capture data across multiple spectral bands, including visible and near-infrared, allowing for the extraction of valuable information about land cover, vegetation health, and geological features. This enables the identification of different materials and the assessment of environmental conditions.
- Accessibility: Electro-optical sensors are widely available on satellites, aircraft, and drones, making them a commonly used technology in geospatial data collection. Their accessibility ensures a consistent and continuous stream of data for monitoring and analysis.
Thermal Imaging: Sensing Heat from Afar.
Thermal imaging is a powerful imaging technology that detects radiation in the thermal infrared range, revealing heat patterns emitted by the Earth's surface. It offers several benefits for geospatial data collection:

- All-weather capability: Thermal imaging can operate in various weather conditions and can penetrate through clouds, smoke, and fog, providing valuable data even in adverse environments. This enables continuous monitoring and detection of thermal anomalies, such as areas of land with abnormal heat signatures.
- Nighttime monitoring: Thermal sensors can capture data during the night when visible light imagery may not be available. This allows for continuous monitoring of temperature variations, helping to identify heat patterns, monitor wildlife activity, and detect heat loss in buildings.
- Environmental monitoring: Thermal imaging is used to monitor and assess temperature variations in natural ecosystems, urban environments, and industrial facilities. It provides insights into urban heat islands, volcanic activity, and the detection of underground water resources.
SAR (Synthetic Aperture Radar): Seeing Through the Darkness.
Synthetic Aperture Radar (SAR) is an imaging technology that uses radio waves to detect and measure the distance, speed, and direction of objects on the Earth's surface. SAR offers several key benefits for geospatial data collection:

- All-weather and day-night imaging: SAR can operate in any weather conditions, day or night, providing continuous imaging capabilities. This ensures uninterrupted monitoring and the ability to capture critical data for applications such as disaster response and maritime surveillance.
- Penetration capability: SAR can penetrate through clouds, vegetation, and even the Earth's surface, allowing for the detection of hidden objects and features. This makes it ideal for applications such as forest structure analysis, subsurface mapping, and monitoring of glaciers and icebergs.
- Fine-resolution imaging: SAR can achieve high spatial resolution, providing detailed imagery that enables the detection of small-scale features and changes on the Earth's surface. This allows for precise monitoring of urban growth, infrastructure changes, and land cover dynamics.
LiDAR (Light Detection and Ranging): Illuminating the Third Dimension.
LiDAR is an imaging technology that uses laser pulses to create three-dimensional maps of the Earth's surface. LiDAR offers several notable benefits for geospatial data collection:

- High-precision elevation data: LiDAR sensors provide highly accurate elevation information, allowing for precise terrain modeling, floodplain mapping, and coastal zone management. This enables detailed topographic analysis and the identification of subtle elevation changes.
- 3D modeling: By capturing the reflected laser pulses from various angles, LiDAR enables the creation of detailed 3D models of the Earth's surface and objects. This aids in urban planning, infrastructure development, and the visualization of complex environments.
- Vegetation structure analysis: LiDAR can penetrate vegetation and capture the vertical structure of forests, providing valuable insights into forest biomass, canopy height, and ecosystem health. This supports forest management, biodiversity assessment, and carbon sequestration estimation.
Infrared Imaging: Seeing Beyond the Visible.
Infrared imaging is a remote sensing technology that detects radiation in the infrared range of the electromagnetic spectrum, providing information about the temperature and composition of the Earth's surface. It offers several benefits for geospatial data collection:
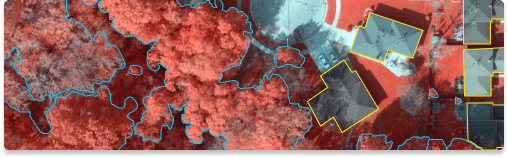
- Thermal analysis: Infrared imaging allows for the detection and analysis of thermal patterns, providing insights into temperature variations and heat distribution on the Earth's surface. This is valuable for monitoring environmental changes, identifying areas of heat stress, and assessing energy efficiency in buildings.
- Vegetation health assessment: Infrared sensors can detect the physiological changes in vegetation, such as water stress and nutrient deficiencies, which are not easily visible to the naked eye. This enables the monitoring of crop health.
- Environmental monitoring: Infrared imaging is instrumental in environmental monitoring, allowing for the detection of pollution and contaminants. It can identify areas of land that are contaminated with hazardous materials, enabling effective remediation and environmental management.
- Fire detection and management: Infrared sensors are crucial in fire detection and management, as they can identify areas of active fire and monitor the spread and intensity of wildfires. This aids in early warning systems, fire behavior analysis, and efficient allocation of firefighting resources.
4. Data pre-processing in Geospatial MLOps.
In the realm of Geospatial MLOPs, data pre-processing assumes a crucial role in ensuring that geospatial datasets are cleaned, formatted, and optimized for effective machine learning (ML) training. Before feeding the data into ML models, it undergoes a series of transformative steps to enhance its quality, consistency, and usability. This essential stage involves employing data cleaning tools, data normalization techniques, and data augmentation methods to prepare the geospatial data for optimal ML performance. Let us delve into the intricacies of data pre-processing and its significance in the geospatial domain.
- Data cleaning serves as the initial step in the pre-processing journey. Geospatial datasets, sourced from diverse sensors and platforms, often contain inherent imperfections such as missing values, outliers, noise, and inconsistencies. To address these issues, data cleaning tools are employed to detect and rectify anomalies, ensuring that the data is accurate, complete, and reliable. This enables geospatial MLOPs practitioners to work with high-quality datasets, minimizing the risk of distorted or erroneous outcomes.
- Data normalization is another crucial aspect of pre-processing in geospatial MLOPs. As geospatial datasets may contain variables with different scales and units, normalizing the data to a common scale enhances the performance and interpretability of ML models. By applying normalization techniques such as feature scaling or standardization, the data is transformed to have zero mean and unit variance, enabling fair comparisons and avoiding biases in ML training. This normalization process facilitates better convergence, stability, and generalization of the models, leading to improved accuracy and efficiency.
- Data augmentation plays a pivotal role in geospatial data pre-processing, especially when dealing with limited or imbalanced datasets. Data augmentation involves generating synthetic data samples by applying various transformations, such as rotation, translation, scaling, or flipping, to existing data instances. This technique effectively expands the training dataset, increases its diversity, and reduces overfitting, empowering the ML models to generalize better and handle unseen scenarios more adeptly. In geospatial MLOPs, data augmentation proves particularly valuable when dealing with tasks such as object detection, land cover classification, or change detection.
Geospatial data pre-processing encompasses the harmonization of various data sources, sensor types, and formats. It involves aligning timestamps, projections, resolutions, and coordinate systems to ensure seamless integration and consistency across datasets. Additionally, geospatial data may undergo spatial resampling or interpolation to match a desired resolution or grid. These pre-processing steps enable the creation of homogeneous datasets, facilitating effective feature extraction, analysis, and modeling.
5. ML Model Training in Geospatial MLOps.
Once the geospatial data has undergone thorough pre-processing, the next critical step in geospatial MLOPs is ML model training. This pivotal stage involves selecting the most suitable ML algorithms and training the models on the pre-processed data to unlock valuable insights and predictions. Even if algorithms and models are commonly used interchangeably, they actually refer to different things:
- An AI/ML algorithm is a set of rules or instructions that a computer program follows to perform a specific task. The algorithm may involve mathematical calculations, statistical analysis, or other computational techniques.
- An AI/ML model is a specific implementation of an AI algorithm that has been trained on data to perform a specific task like image segmentation or object detection. The model is essentially the result of the algorithm's application to a particular problem, and it reflects the learned patterns in the data.
To better understand the difference between AI/ML algorithms and AI models, we can draw an analogy using the process of constructing a building:
- An AI/ML algorithm can be likened to the architectural blueprint of a building. It outlines the design principles, rules, and guidelines for constructing the building. In machine learning, an algorithm provides the framework and methodology for processing and analyzing data. It defines the step-by-step instructions and computations needed to learn patterns from the data and make predictions or classifications. Just as an architectural blueprint guides the construction process, an ML algorithm guides the learning and decision-making process of the model.
- An AI/ML model is comparable to the physical structure that is constructed based on the architectural blueprint. It represents the tangible manifestation of the design and principles outlined in the blueprint. Similarly, an ML model is the learned representation or structure that is created by applying the ML algorithm to a specific dataset. It embodies the knowledge and relationships learned from the data during the training phase. Just as the physical structure provides the functionality and purpose of the building, an ML model provides the capability to make predictions or perform specific tasks based on the learned patterns.
The first step in ML model training is algorithm selection. Geospatial MLOPs practitioners must carefully consider the nature of their problem, the characteristics of the data, and the desired outcomes to choose the most appropriate ML algorithms. For geospatial analysis tasks such as land cover classification, object detection, or spatial regression, different algorithms may yield varying levels of accuracy, interpretability, and computational efficiency. It is crucial to strike a balance between model complexity and performance to ensure efficient processing and meaningful results.
In the realm of machine learning, various algorithms are utilized to tackle different types of learning tasks, namely supervised learning, unsupervised learning, semi-supervised learning and reinforcement learning:
- Supervised Learning: In supervised learning, the model is trained using labeled data, where the input samples are paired with corresponding target labels. The goal is to learn a mapping function that can predict the labels of new, unseen data based on the learned patterns from the labeled examples. In geospatial MLOps, supervised learning can be used for tasks such as land cover classification, object detection, or image segmentation. By leveraging labeled training data, supervised learning enables the development of models that can accurately classify or identify specific features in geospatial data.
- Unsupervised Learning: Unsupervised learning involves training models on unlabeled data, where there are no predefined target labels. The objective is to uncover hidden patterns, structures, or relationships within the data. In the geospatial domain, unsupervised learning techniques like clustering or dimensionality reduction can be applied. Clustering algorithms can group similar geospatial data points together, aiding in tasks such as identifying similar land cover areas or detecting anomalies. Dimensionality reduction techniques, such as PCA, can help reduce the complexity of high-dimensional geospatial datasets while preserving their essential characteristics.
- Semi-Supervised Learning: Semi-supervised learning combines elements of both supervised and unsupervised learning. It involves training models on a combination of labeled and unlabeled data, where the labeled data is scarce or expensive to obtain. By utilizing the additional unlabeled data, the model can learn more robust representations or discover underlying structures that improve its performance. In geospatial MLOps, semi-supervised learning can be valuable when labeled data is limited, but unlabeled data is readily available. This approach can enhance tasks such as land cover mapping, where the model can leverage both labeled samples and the larger pool of unlabeled geospatial data to make more accurate predictions.
- Reinforcement Learning: Reinforcement learning (RL) involves training agents to make sequential decisions in an environment to maximize cumulative rewards. RL algorithms learn through trial and error by interacting with the environment and receiving feedback in the form of rewards or penalties. In geospatial MLOps, reinforcement learning can be applied to optimize resource allocation, route planning, or environmental monitoring tasks. For example, RL can be used to develop models that optimize the path of a satellite for data collection, considering factors such as cloud cover or image quality. By iteratively learning and refining the decision-making process, reinforcement learning enables the development of adaptive and intelligent geospatial systems.
Each category of learning has its own set of algorithms that serve specific purposes. Let's explore these algorithms in the context of their respective learning tasks:
|
Name |
Type |
Description |
Benefits |
|
Convolutional Neural Networks (CNNs) |
Supervised Learning |
CNNs are deep neural networks specifically designed for processing grid-like data such as images. They consist of convolutional layers that extract spatial features, followed by pooling layers for dimensionality reduction, and fully connected layers for classification or regression. |
CNNs are highly effective for tasks such as land cover classification, object detection, and image segmentation in geospatial MLOps. They can learn spatial representations and capture complex patterns in geospatial imagery, allowing for accurate and automated analysis. |
|
Recurrent Neural Networks (RNNs) |
Supervised Learning |
RNNs are neural networks designed for handling sequential data. They have recurrent connections that allow information to persist over time, making them suitable for tasks involving temporal dependencies. |
RNNs are useful for geospatial time series analysis, such as predicting land surface temperature, analyzing climate patterns, or detecting changes over time. They can capture temporal dependencies in the data, enabling accurate predictions and analysis. |
|
Decision Trees |
Supervised Learning |
Decision trees are tree-based models that partition the feature space based on a series of decision rules. Each internal node represents a decision based on a feature, and each leaf node represents a class or a value. |
Decision trees are interpretable and can handle both classification and regression tasks. They can be used for land cover classification, terrain analysis, and predicting environmental variables. Decision trees can capture complex decision boundaries and handle both numerical and categorical geospatial data. |
|
Support Vector Machines (SVMs) |
Supervised Learning |
SVMs aim to find an optimal hyperplane that separates classes in the feature space. They maximize the margin between classes and can handle linear and non-linear classification tasks using different kernels. |
SVMs are effective for land cover classification, object recognition, and anomaly detection in geospatial MLOps. They can handle high-dimensional data, generalize well to unseen samples, and robustly handle noise. |
|
Generative Adversarial Networks (GANs) |
Unsupervised Learning |
GANs consist of a generator network and a discriminator network that compete against each other in a two-player game. The generator generates synthetic samples, and the discriminator tries to distinguish between real and generated samples. |
GANs can be used for data augmentation, generating realistic synthetic geospatial images, or enhancing the diversity of training data. They enable the creation of additional training samples, leading to improved model performance and generalization. |
|
K-means Clustering |
Unsupervised Learning |
K-means clustering is an iterative algorithm that partitions data into K clusters based on their similarity. It aims to minimize the within-cluster sum of squared distances. |
K-means clustering can be used for unsupervised land cover classification, clustering similar satellite images, or identifying clusters of similar features in geospatial data. |
|
Hierarchical Clustering |
Unsupervised Learning |
Hierarchical clustering builds a hierarchy of clusters by recursively merging or splitting clusters based on their similarity or dissimilarity. |
Hierarchical clustering can be used for various geospatial tasks such as land cover classification, anomaly detection, and image segmentation. It helps identify natural groupings or patterns in geospatial data based on their spatial relationships. The hierarchical structure allows for the exploration of clusters at different levels of granularity, providing insights into the spatial organization of the data. |
|
Principal Component Analysis (PCA) |
Unsupervised Learning |
PCA is a dimensionality reduction technique that transforms high-dimensional data into a lower-dimensional space by capturing the most significant variations in the data through orthogonal linear transformations. |
PCA can be used to reduce the dimensionality of geospatial data, extract informative features, and visualize high-dimensional datasets. It aids in data compression, noise reduction, and visualization of geospatial patterns. |
|
Self-Training |
Semi-Supervised Learning |
Self-training involves using a small set of labeled data along with a larger set of unlabeled data. The model initially trains on the labeled data and then uses its predictions on the unlabeled data to expand the training set iteratively. |
Self-training can be beneficial when labeled data is limited or expensive to acquire in geospatial MLOps. It leverages unlabeled data to improve model performance and generalization by iteratively incorporating pseudo-labeled data. |
|
Co-Training |
Semi-Supervised Learning |
Co-training involves training multiple models on different subsets of the data and using their predictions on unlabeled data to iteratively update and refine each model. |
Co-training can effectively utilize unlabeled geospatial data to improve model performance. It leverages the complementary information captured by multiple models and enhances learning from limited labeled data. |
|
Multi-view Learning |
Semi-Supervised Learning |
Multi-view learning leverages multiple distinct representations or views of the same data to improve learning performance. Each view provides complementary information that contributes to better model training. |
Geospatial data often has multiple sources or modalities, such as satellite imagery, aerial photography, and ground-based sensors. Multi-view learning enables the integration of diverse geospatial data sources, leading to more accurate and comprehensive models. |
|
Q-Learning |
Reinforcement Learning |
Q-learning is a model-free reinforcement learning algorithm that aims to find an optimal policy for an agent to maximize cumulative rewards in a Markov Decision Process (MDP) environment. |
Q-learning can be employed for tasks like route optimization, autonomous navigation, and resource management in geospatial applications. It allows agents to learn optimal decision-making strategies through exploration and exploitation of geospatial environments. |
|
Deep Q-Networks (DQN) |
Reinforcement Learning |
DQN combines deep neural networks with Q-learning to approximate Q-values in high-dimensional state spaces. It utilizes a replay memory and target network to stabilize and accelerate the learning process. |
DQN can be applied to geospatial problems requiring reinforcement learning, such as optimizing UAV flight paths, land-use planning, and natural resource management. It enables efficient learning and decision-making in complex geospatial environments. |
|
Policy Gradient Methods |
Reinforcement Learning |
Policy gradient methods directly learn a parameterized policy that maps states to actions through gradient ascent. They optimize the policy by estimating the gradient of expected rewards. |
Policy gradient methods can be used in geospatial tasks where the agent's actions directly impact the environment, such as wildfire management, disaster response, or ecosystem preservation. They enable learning optimal policies without explicitly modeling the environment dynamics. |
In addition to selecting the appropriate ML algorithms, the availability of representative training data is crucial for achieving robust models in geospatial MLOPs. However, in some cases, acquiring sufficient and diverse real-world data may pose challenges. To address this issue, the use of synthetic data generated through data augmentation or simulation techniques can be beneficial. Synthetic data helps to enrich the training dataset, augment the variety of samples, and improve the model's ability to generalize and handle unseen scenarios.
During the model training phase, geospatial MLOPs practitioners fine-tune the selected algorithms by iteratively adjusting the model's parameters and optimizing the objective function. This process involves splitting the pre-processed data into training and validation sets, with the latter serving as a means to assess the model's performance and prevent overfitting. By leveraging optimization techniques such as gradient descent, stochastic gradient descent, or evolutionary algorithms, the models learn from the training data, updating their internal parameters to minimize errors and improve predictions.
6. Using Data labeling tools to simplify computer vision-based Geospatial model training.
Choosing the right algorithm can be daunting. This step can be skipped by using a dedicated geospatial MLOps solution such as Deep Block. There, you can choose from a selection of models that can be trained into custom models or use pre-trained models that can deliver results at the push of a button:

- Object detection: Object detection can identify and localize objects in an image or video stream. This model is used in various applications, such as aerial reconnaissance, target tracking, and vehicle identification.
- Image segmentation: Image segmentation works by dividing an image into several segments, each with a unique label, to make it easier to analyze and extract information from the image. It is used for target identification, terrain analysis, and building mapping.
- Change detection: Change Detection (CD) based on remote sensing technology is used to discover and identify discrepancies in ground objects using two (bi-temporal) or more (multi-temporal) images taken by the same type of sensor.
To build efficient and accurate models, the data used for training must be appropriately labeled. Data labeling involves tagging or annotating data to provide context and meaning to the detector, allowing it to learn patterns and make accurate predictions.
Data labeling, also known as data annotation, is the process of adding metadata or labels to data to make it more informative and easier to analyze. However, the data is usually massive and unstructured, making it challenging to analyze and extract meaningful insights. Data labeling helps to organize and structure the data, making it easier to use for machine learning models. For example, in object detection tasks, such as identifying military equipment or personnel in satellite imagery, data labeling involves marking the location, size, and shape of each object of interest. Similarly, in image segmentation tasks, data labeling involves assigning a label to each pixel in the image to indicate the class it belongs to, such as land, water, or buildings.
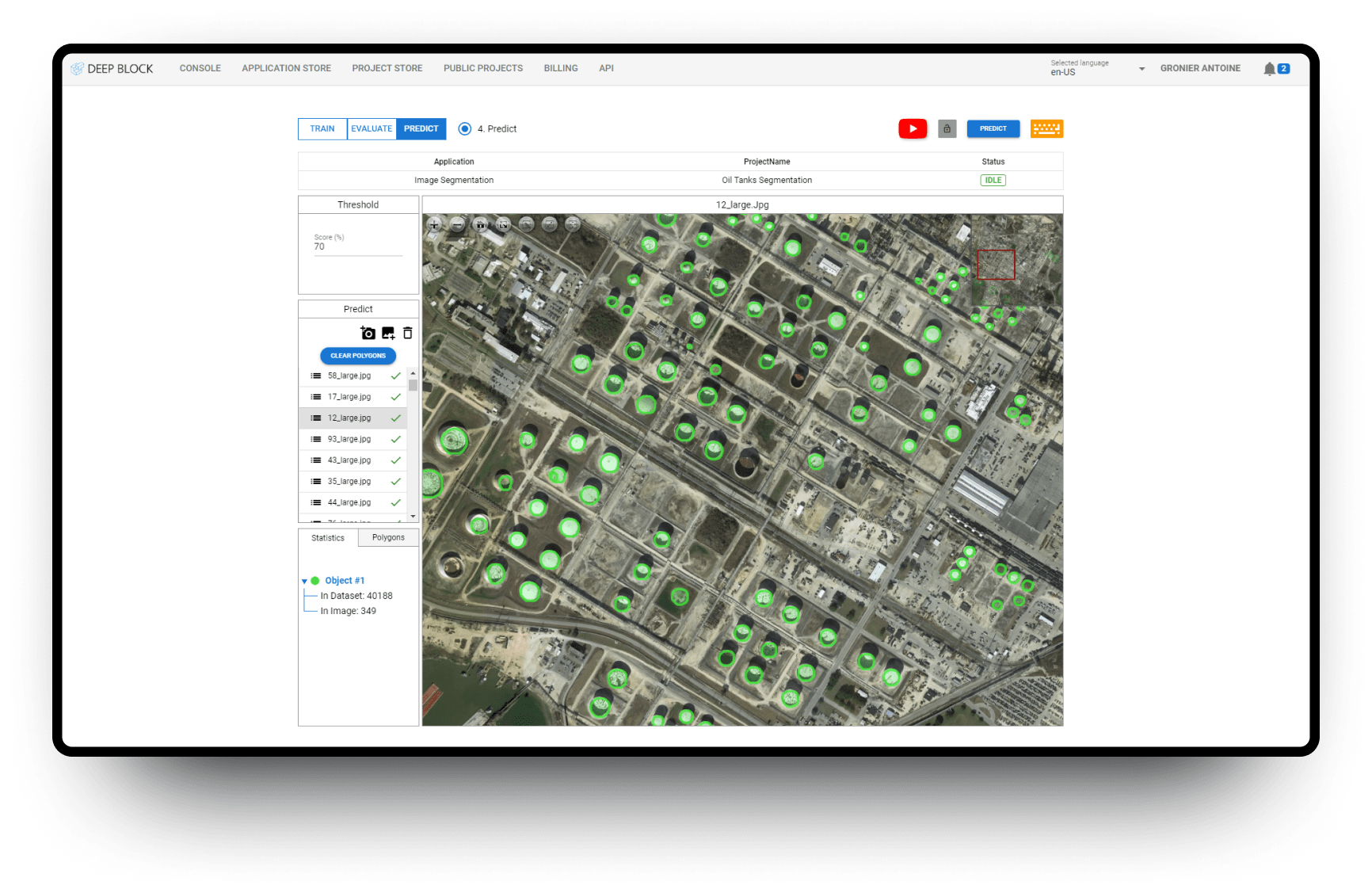
There are different types of data labeling methods, including manual and automatic labeling. Manual labeling involves the use of human annotators to manually add labels to data. This process is time-consuming but it provides more accurate and reliable results. Automatic labeling, on the other hand, uses AI algorithms to label data automatically, based on predefined rules or machine learning models. This process is faster and more scalable, but it may not always produce accurate results.
Data labeling remains a labor-intensive task that requires skilled human annotators to go through large volumes of data and accurately label each item. The accuracy and quality of the labels are essential for the success of the machine learning models. Hence, it is crucial to have a well-defined data labeling process and quality control mechanisms in place:
- Define clear labeling guidelines: To ensure consistency in data labeling, it is important to define clear guidelines for annotators. These guidelines should cover the types of labels to be used, the format of the labels, and any specific rules or criteria for labeling.
- Use multiple annotators: To ensure the accuracy and reliability of data labeling, it is recommended to use multiple annotators to label the same data. This helps to identify any inconsistencies or errors in the labeling and improve the quality of the data.
- Use tools for automatic labeling: To improve the efficiency and scalability of data labeling, it is recommended to use software tools for automatic labeling. These tools can help to speed up the labeling process.
- Monitor the labeling process: It is important to monitor the data labeling process to ensure that it is progressing according to the defined guidelines and quality standards. This can be done by regularly reviewing the labeled data and providing feedback to annotators.
7. Model Evaluation for Geospatial MLOps.
Once an ML model has been trained, it is crucial to evaluate its performance to ensure its accuracy and reliability in handling geospatial data. Model evaluation is a critical step that involves the assessment of various performance metrics and techniques to measure the model's effectiveness. This evaluation provides valuable insights into the model's capabilities and helps determine its suitability for geospatial applications.
One common approach to evaluating ML models in geospatial MLOPs is through the use of performance metrics. These metrics quantify the model's predictive performance and provide a comprehensive assessment of its strengths and weaknesses. Here are some commonly used performance metrics in geospatial ML model evaluation:
- Precision: Precision measures the proportion of correctly predicted positive samples out of all samples predicted as positive. In geospatial applications, precision helps determine the accuracy of the model in identifying specific land cover classes, objects, or features of interest. A high precision indicates a low rate of false positives.
- Recall: Recall, also known as sensitivity or true positive rate, measures the proportion of correctly predicted positive samples out of all actual positive samples. In geospatial MLOPs, recall assesses the model's ability to correctly identify all instances of a particular class or feature. A high recall indicates a low rate of false negatives.
- F1 Score: The F1 score is the harmonic mean of precision and recall, providing a balanced measure of the model's overall performance. It combines precision and recall into a single metric and is particularly useful when the dataset is imbalanced. The F1 score is widely used in geospatial ML model evaluation to assess the model's overall performance.
- Accuracy: Accuracy measures the proportion of correctly classified samples out of the total number of samples. It provides a general measure of the model's correctness and is often used as a baseline metric in geospatial ML model evaluation. However, accuracy alone may not be sufficient, especially when dealing with imbalanced or skewed datasets.
Evaluating a model in geospatial MLOps involves several steps, including the use of evaluation datasets and labeling tools:
- Create an Evaluation Datasets: In geospatial MLOps, evaluation datasets are carefully curated sets of data that are separate from the training data. These datasets are used to assess the model's performance on unseen or held-out data, providing an unbiased evaluation of its capabilities. The evaluation datasets should be representative of the real-world scenarios the model will encounter.
- Prepare the Data: Before evaluating the model, the evaluation datasets need to be prepared. This involves preprocessing steps similar to the ones applied during training, such as data cleaning, normalization, and feature engineering. The data should be transformed into a format that the model can process effectively.
- Label the data: Labeling tools like the one made by Deep Block are utilized in geospatial MLOps to annotate or label the evaluation datasets. These tools allow human experts to assign ground truth labels or annotations to the data, enabling the comparison of the model's predictions with the actual values.
- Launch the Model Prediction: Once the evaluation datasets are labeled, the model's predictions are generated for each sample in the dataset. The model processes the input data and produces output predictions based on the learned patterns and relationships. These predictions are then compared against the ground truth labels provided by the labeling tools.
- Obtain a grade: After the prediction is done, the system will calculate the performance metrics based on the comparison between the predicted labels and the ground truth labels.
Model evaluation in geospatial MLOps is an iterative process. The initial evaluation provides insights into the model's strengths and weaknesses. Based on the evaluation results, adjustments can be made to the model, data preprocessing techniques, or training strategies to improve performance. The model is then reevaluated using the updated configuration, and the process continues until satisfactory results are achieved.
By leveraging evaluation datasets and labeling tools, geospatial MLOps practitioners can objectively assess the performance of their models. This evaluation process helps in understanding how well the model generalizes to unseen data, identifying areas for improvement, and guiding decisions regarding model deployment and further iterations of the MLOps pipeline.
8. Model Deployment in Geospatial MLOps.
In Geospatial MLOps, computer vision models are trained on large datasets to detect and classify objects, perform image segmentation, and identify changes in the environment over time. However, the real value of these models is realized when they are deployed in operational environments. Here are the different steps to achieve this:
- Preparing the Model for Deployment: Before deploying a computer vision model, it is important to ensure that it is compatible with the hardware and software infrastructure of the operational environment. This includes optimizing the model for performance and memory usage on the target hardware, such as a remote sensing platform or a ground-based system. The model must also be packaged into a deployable format, such as a Docker container, that can be easily deployed and managed in the operational environment. The container should include all the necessary dependencies, such as the model's architecture, weights, and pre-processing code, as well as any required libraries and tools.
- Deploying the Model: Once the model is prepared, it can be deployed to the operational environment. The deployment process involves installing the container on the target system and configuring it to receive input data and generate output results. In Geospatial MLOps, computer vision models may be deployed in a variety of settings, including ground-based sensors, unmanned aerial vehicles (UAVs), and satellites. Each environment presents unique challenges, such as limited bandwidth, processing power, and memory, that must be taken into account during deployment.
- Input Data Processing: Once the model is deployed, it must be configured to receive input data in the appropriate format. This may involve pre-processing the data to ensure that it is in a format that can be understood by the model. For example, in geospatial applications, input data may be in the form of satellite imagery or LiDAR data. The data may need to be pre-processed to remove noise, enhance features, and adjust for atmospheric conditions. The pre-processing steps will depend on the specific model and the nature of the input data.
- Model Execution: After the input data is processed, it is fed into the deployed model for execution. The model generates output results, such as object detection, image segmentation, or change detection, based on the input data and the model's training. The output results may be in the form of raw data, such as pixel values or feature vectors, or they may be in a more user-friendly format, such as a visualization or a report. The output results may also be used as input to other systems or models for further analysis and decision-making.
- Result Analysis and Feedback: Finally, the output results must be analyzed and interpreted in the context of the operational environment. This may involve visualizing the output results to identify patterns and trends, or it may involve statistical analysis to identify significant changes over time. The results may also be compared to ground truth data, such as data collected by human operators, to validate the model's performance and identify areas for improvement. The feedback generated from this analysis can be used to refine the model and improve its performance in future deployments.
9. Model Monitoring and Maintenance in Geospatial MLOps.
The deployment of these models is not a one-time process; rather, it is an ongoing effort that requires continuous monitoring and maintenance to ensure optimal performance.
A study by Accenture found that companies that regularly update and maintain their machine learning models achieve an average improvement of 25% in model performance.
- Monitoring Performance: Once the ML model is deployed, it is essential to monitor its performance on an ongoing basis. This involves collecting real-time or periodic data from the operational system and comparing the model's predictions with the actual outcomes. Monitoring can include tracking performance metrics, such as accuracy, precision, recall, or other domain-specific metrics, to ensure that the model is delivering accurate results.
- Anomaly Detection: Model monitoring also involves the detection of anomalies or deviations from expected behavior. By monitoring the model's predictions and comparing them with the ground truth, any significant discrepancies or outliers can be identified. Anomaly detection techniques, such as statistical methods or machine learning algorithms, can be applied to highlight potential issues or drift in model performance.
- Feedback Loops: To improve and maintain the ML model's performance, feedback loops are crucial. Feedback can come from various sources, including user feedback, domain experts, or external data sources. This feedback can be used to identify model weaknesses, uncover new patterns or trends, and guide model updates or retraining. It helps in iteratively refining the model and adapting to evolving geospatial conditions.
- Continuous Data Collection: Model maintenance in geospatial MLOps often requires continuous data collection. By collecting new data from the operational environment, the model can be exposed to diverse and up-to-date scenarios. This data can be used to expand the training dataset, retrain the model periodically, or augment the existing training data to capture changing patterns or emerging trends.
- Labeling Tools in Maintenance: Labeling tools also play a role in model maintenance. As new data is collected, it needs to be labeled or annotated to generate ground truth labels for evaluation and retraining. Labeling tools enable the efficient and accurate annotation of new data, helping to maintain a high-quality training dataset. Additionally, labeling tools can be used to create labeled datasets for specific use cases or tasks, allowing the model to adapt and specialize in targeted geospatial applications.
- Version Control and Documentation: In geospatial MLOps, maintaining proper version control and documentation is essential for model maintenance. It enables tracking of model versions, code changes, and data updates. Version control helps in reproducing and comparing different model iterations, ensuring transparency, reproducibility, and accountability. Documentation provides a record of the model's configuration, training process, evaluation results, and any changes made during maintenance, facilitating knowledge transfer and collaboration among stakeholders.
By implementing robust monitoring mechanisms, establishing feedback loops, leveraging labeling tools, and conducting regular updates and maintenance activities, geospatial MLOps practitioners can ensure the long-term performance and reliability of ML models in the dynamic geospatial domain.
In conclusion, Geospatial MLOps is a game-changer in utilizing geospatial data and machine learning. By combining advanced algorithms and vast amounts of geospatial information, it offers valuable insights and solutions across multiple fields. From environmental monitoring and urban planning to agriculture and disaster management, Geospatial MLOps finds application in diverse domains.
Collaboration between geospatial experts and machine learning practitioners is key to driving innovation in this field. As we continue to refine algorithms, develop robust pipelines, and leverage cutting-edge technologies, Geospatial MLOps will reshape how we analyze geospatial data and make informed decisions.
Geospatial MLOps empowers us to unlock the full potential of geospatial data through machine learning. By embracing this technology, we can gain a deeper understanding of our world, address complex challenges, and pave the way for a more connected and intelligent future.