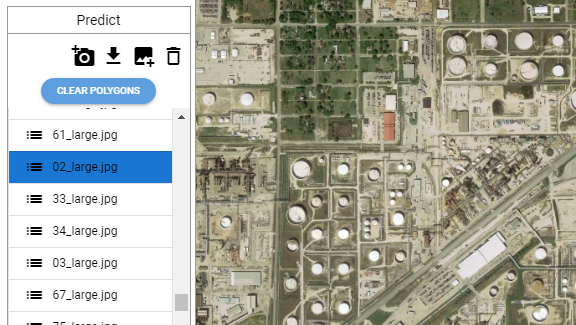
Image segmentation
Overview
What is image segmentation?

Image segmentation is the process of partitioning an image into multiple segments, or regions, each of which corresponds to a different object or part of the scene. The goal of image segmentation is to simplify and/or change the representation of an image into something that is more meaningful and easier to analyze.
With Deep Block, you can isolate the image's constituent parts under their respective categories or class labels. This way you can automate your computer vision tasks for:
-
Object recognition: By segmenting an image into its constituent objects, it becomes easier to recognize and identify each object individually.
-
Morphology: Image segmentation can be used to extract information about the objects or regions in an image, such as size, shape, color, and texture.
-
Image classification: The area extracted through segmentation can be a separate image and used as input for an image classification task.
Through this, instances(polygons) can be classified more precisely and analyzed in more detail. -
Background subtraction: Image segmentation can be used to separate the foreground objects from the background in an image.
-
Measurement: Segmentation can also be used for measuring the area and length of objects and other measurement tasks.
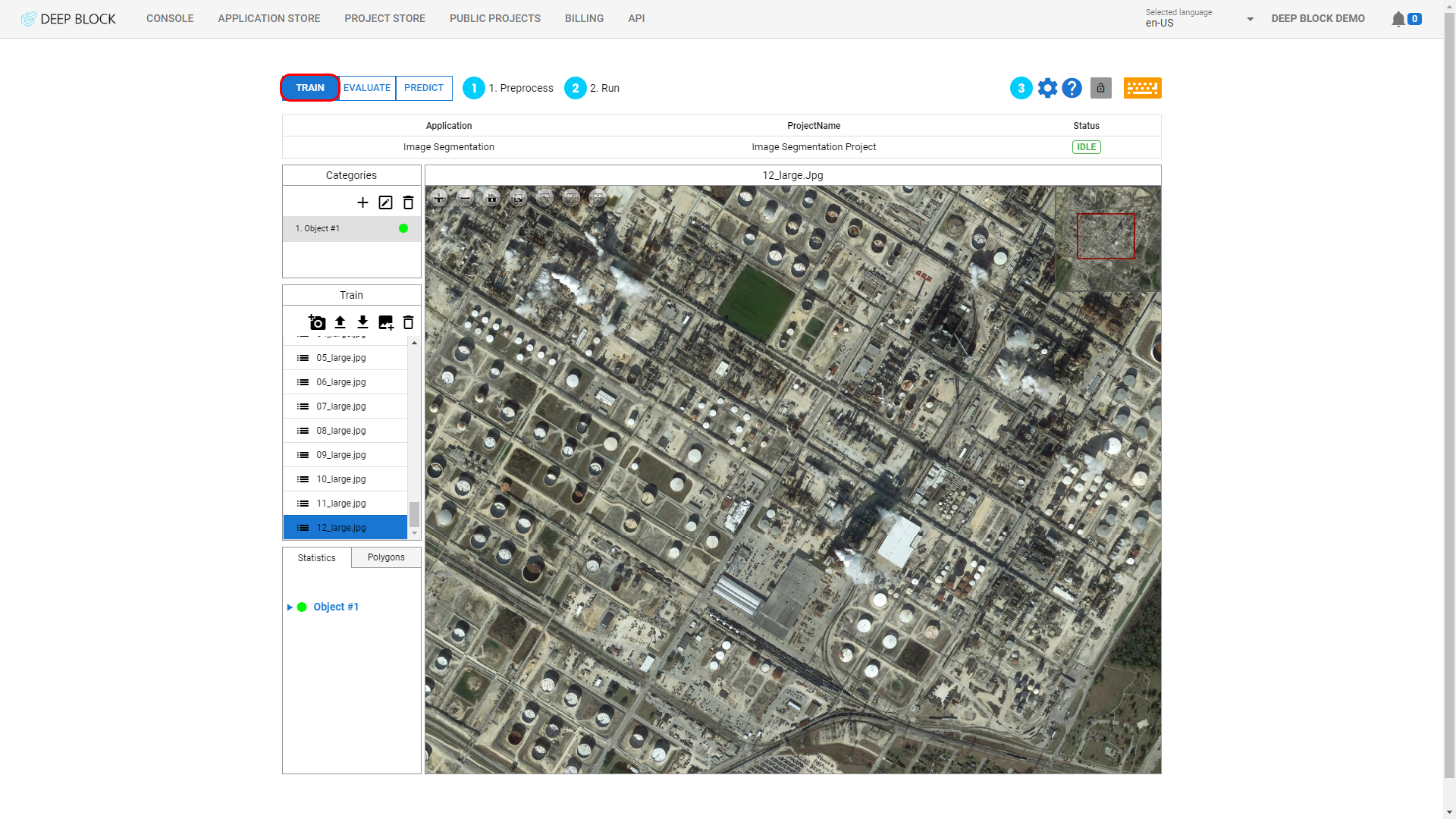

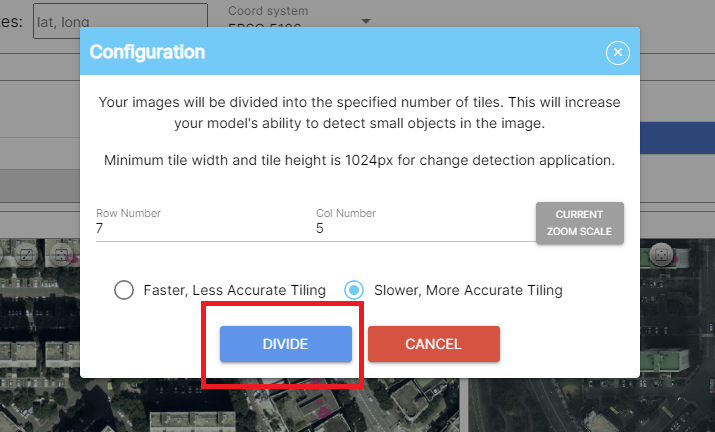
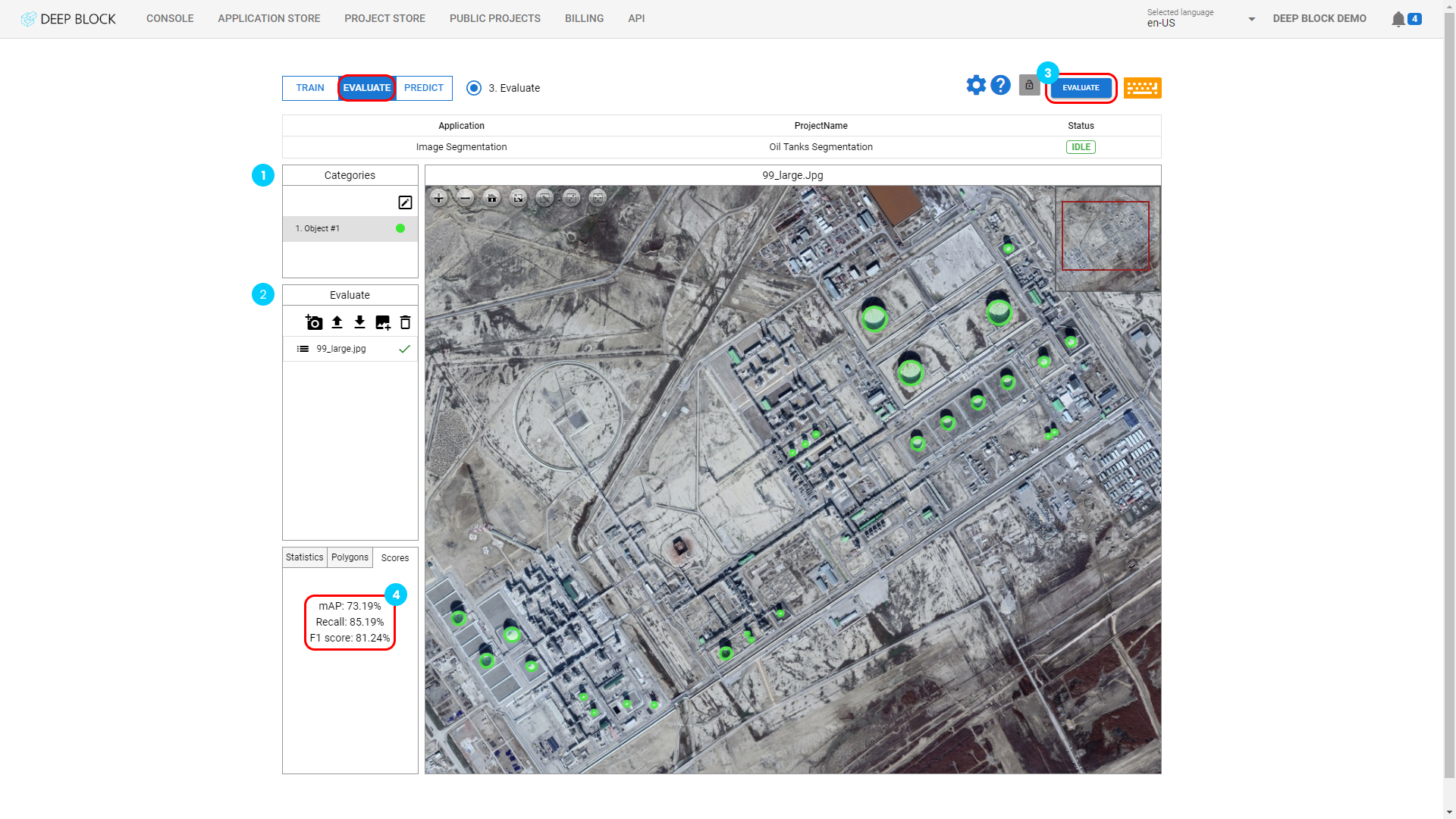
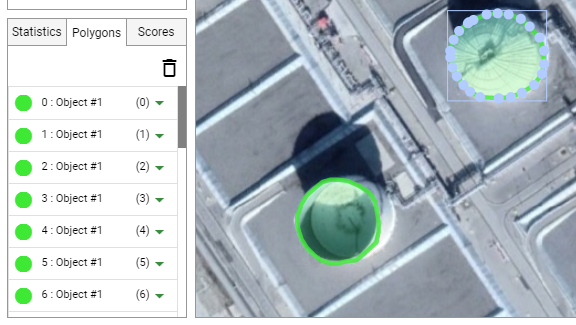
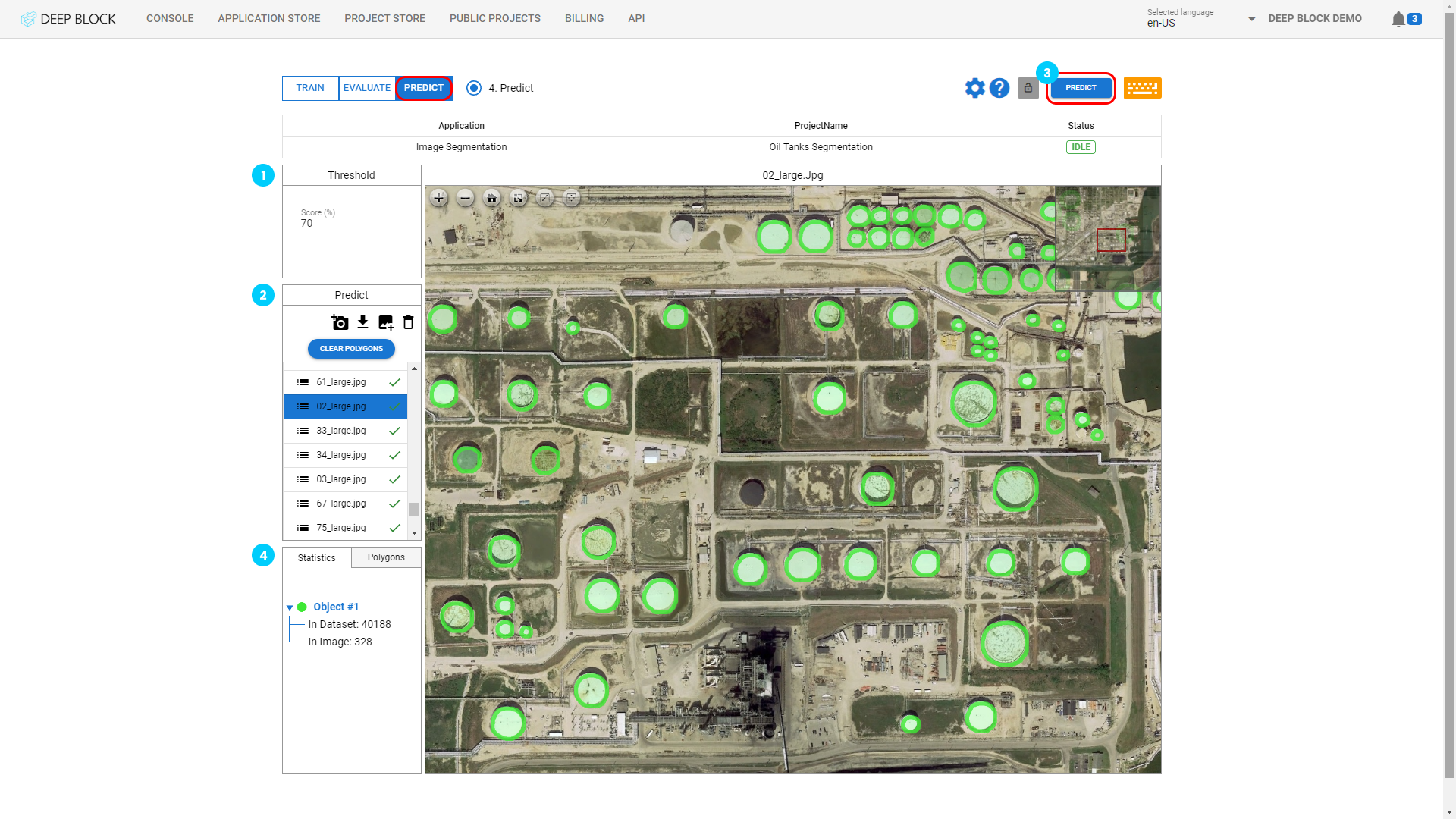
- Click on "
 " to add an image via your webcam.
" to add an image via your webcam. - Click on "
 " to download the inference result as JSON file. (COCOJSON style or GEOJSON)
" to download the inference result as JSON file. (COCOJSON style or GEOJSON) - Click on "
 " to import images that you wish to use.
" to import images that you wish to use. - Click on "
 " to remove an image after selecting it.
" to remove an image after selecting it. - If a prediction has already been made, click on "CLEAR POLYGONS" to remove all polygons.
Image file formats supported are: png, webp jpg, geotiff, tiff, bmp, and jp2 (10GB max file size). If you want to upload a bigger file, contact us.