- Click on "
 " to add a category.
" to add a category. - Click on "
 " to rename a category after selecting one. This option is also available by clicking right on the desired category.
" to rename a category after selecting one. This option is also available by clicking right on the desired category. - Click on "
 " to remove a category after selecting one. This option is also available by clicking right on the desired category.
" to remove a category after selecting one. This option is also available by clicking right on the desired category.
Caution: Removing a category will remove every labeled data belonging to that category. - Click on the colored "
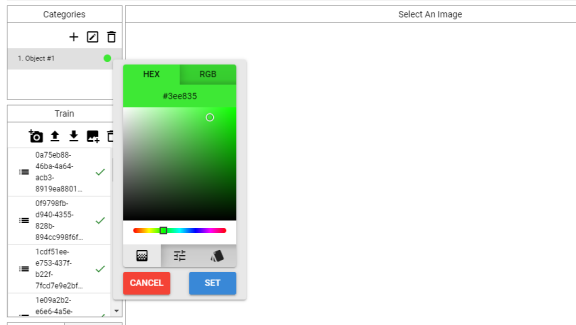
 " to display the Categories color panel. You can choose your preferred color using HEX or RBG values, or directly by selecting the color of your choice.
" to display the Categories color panel. You can choose your preferred color using HEX or RBG values, or directly by selecting the color of your choice.
- Click on "
 " to add an image via your webcam.
" to add an image via your webcam. - Click on "
 " to upload a JSON File. JSON files are often used to store the annotations or labels for the images.
" to upload a JSON File. JSON files are often used to store the annotations or labels for the images. - Click on "
 " to download the JSON file for the current project.
" to download the JSON file for the current project. - Click on "
 " to import images that you wish to label.
" to import images that you wish to label. - Click on " " to remove an image after selecting it.
Image file formats supported are: png, jpg, webp, tiff, bmp, geotiff, and jp2 (10GB max for free users).
JSON file format supported: COCO JSON

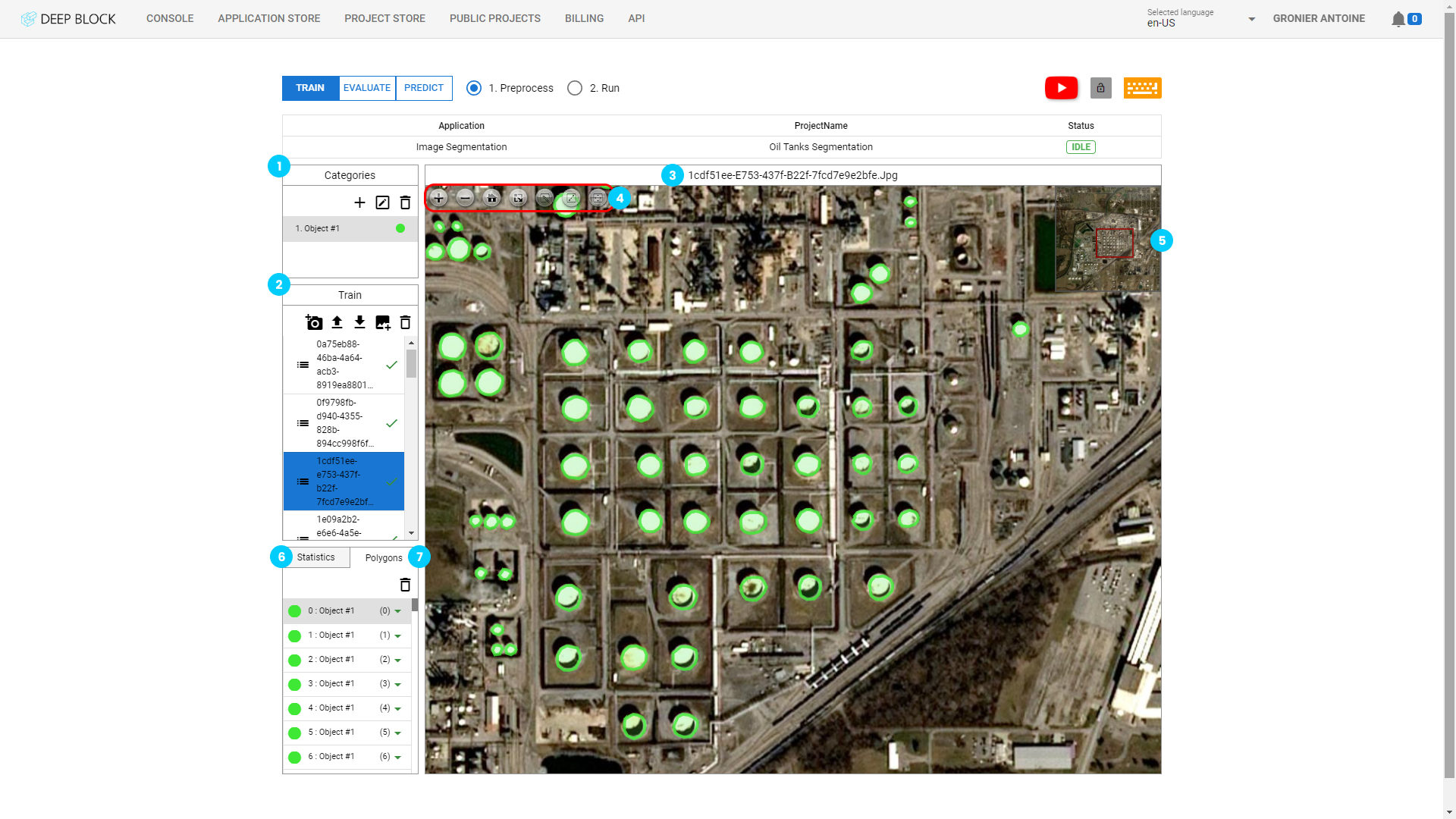
4 - Labeling toolbox
The labeling toolbox is a set of tools that helps you navigate and annotate all your images with ease. It can be found at the top-left corner of the Image panel.
- Click on "
 " to zoom in on the picture.
" to zoom in on the picture. - Click on "
 " to zoom out of the picture.
" to zoom out of the picture. - Click on "
 " to reset the view.
" to reset the view. - Click on "
 " to toggle the full-screen mode.
" to toggle the full-screen mode. - Click on "
 " to toggle the draw mode.
" to toggle the draw mode. - Click on "
 " to toggle the select mode.
" to toggle the select mode. - Click on "
 " to toggle the move mode.
" to toggle the move mode.




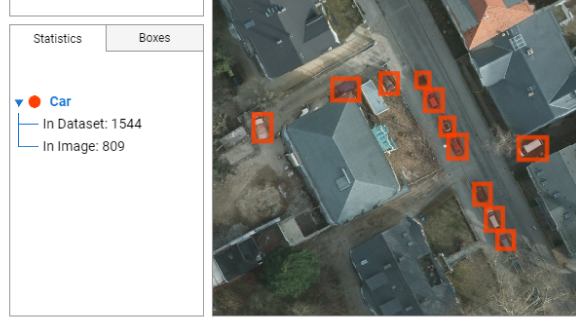
7 - Polygons or Boxes
The Polygons or Boxes tab lists each object or area labeled within the selected image. Each annotation of this list can be individually selected to display its current position on the image.
- Click " " after selecting an annotation in the list to remove the annotation.
Caution: this process can not be undone. - Click on the "
 " or click right on each annotation in the list to switch its category.
" or click right on each annotation in the list to switch its category.