Discover the potential of multi-modal learning and its applications in GEOAI & Remote Sensing.
Understanding Multi-Modal Learning
Multi-modal learning refers to the use of multiple sources of data or modalities to improve learning and decision-making processes.
In the context of machine learning, multimodal deep learning involves the use of deep neural networks to process and analyze information from multiple modalities, such as text, images, audio, and other data types. This approach aims to model complex relationships and interactions between different types of data, providing a more comprehensive understanding of the underlying information. Multimodal deep learning has applications in various fields, including computer vision, natural language processing, and audio processing.
Key concepts and components of multimodal deep learning include:
-
Multimodal Data Fusion:
- Combining information from different modalities to create a unified representation. This could involve fusing data from sources like images, text, and audio to capture rich and diverse features.
-
Cross-Modal Learning:
- Enabling the model to learn relationships between different modalities. This involves training the model on examples where information from multiple modalities is present, allowing it to understand how these modalities relate to each other.
-
Multimodal Representation Learning:
- Learning a shared representation space where information from different modalities can be aligned. This shared representation facilitates joint understanding and processing of multimodal data.
Multimodal deep learning is valuable in situations where information is naturally expressed across multiple modalities, and a comprehensive understanding requires the joint analysis of these modalities. It has the potential to enhance the performance of various artificial intelligence applications by enabling models to learn from and leverage diverse sources of information.
In the context of GEOAI, it involves integrating different types of data, such as electro-optical image, LIDAR image, and NIR spectrum image, to gain a more comprehensive understanding of the Earth's surface and its features.
By combining information from various modalities, multi-modal learning can enhance the accuracy and reliability of analysis and prediction tasks in remote sensing image analysis.
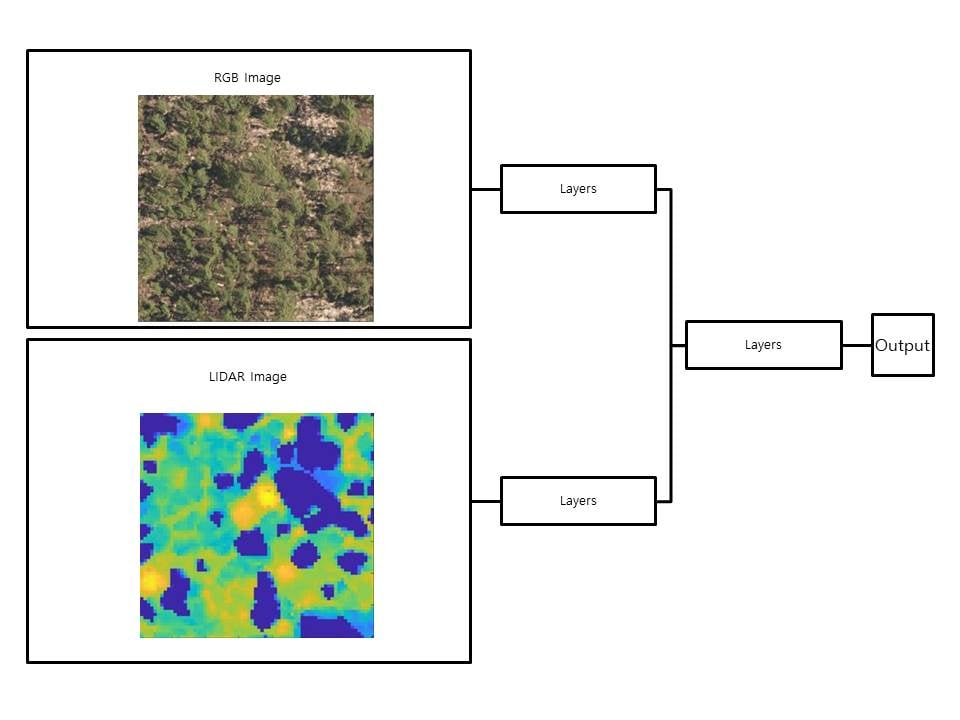
Take a look at the image below, showcasing a typical multi-modal deep learning model architecture designed for tasks such as object detection and image segmentation.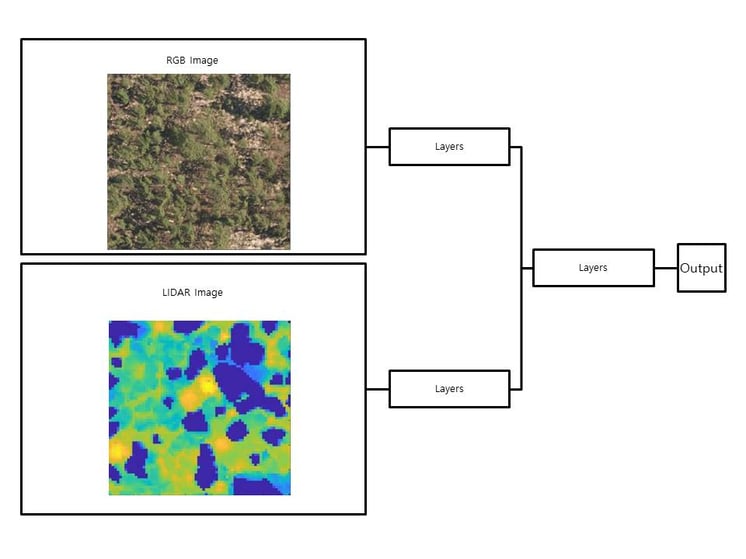
One of the key advantages of multi-modal learning is its ability to capture complementary information from different sources. Each modality provides a unique perspective on the observed phenomenon, and by fusing these perspectives together, we can obtain a more complete and accurate representation of the underlying reality. For example, combining visible and near-infrared (NIR) images can help identify vegetation areas more effectively, as vegetation reflects NIR light differently than other objects. This allows for more accurate classification and mapping of land cover and vegetation types.
Furthermore, multi-modal learning can also leverage the strengths of different modalities to compensate for their individual weaknesses. For instance, while optical imagery can provide detailed information about surface features, it may be limited in its ability to penetrate clouds or capture data in low-light conditions. In such cases, incorporating data from other modalities, such as radar or thermal sensors, can provide valuable insights and improve the overall analysis.
Overall, understanding multi-modal learning is crucial for unlocking the full potential of GEOAI. By harnessing the power of multiple modalities and integrating diverse data sources, we can improve the accuracy, robustness, and efficiency of remote sensing image analysis, leading to better insights and decision-making in various applications.
Benefits of Multi-Modal Learning in Remote Sensing Image Analysis
Multi-modal learning offers several key benefits in remote sensing image analysis. One of the primary advantages is improved accuracy. By combining data from different modalities, we can leverage the unique information provided by each modality to enhance the analysis process. This can result in more accurate and reliable identification and mapping of land cover, vegetation types, and other features of interest.
Another benefit of multi-modal learning is increased robustness and resilience. By incorporating multiple sources of data, we can reduce the impact of noise, outliers, and missing information in individual modalities. This makes the analysis more robust to variations in data quality and ensures more reliable results.
Furthermore, multi-modal learning enables better feature representation and extraction. Different modalities capture different aspects of the observed phenomenon, and by combining them, we can create more comprehensive and discriminative feature representations. This allows for more effective feature extraction and can improve the performance of various tasks, such as object detection, segmentation, and change detection.
In addition, multi-modal learning can also enhance the interpretability and explainability of the analysis. By integrating diverse sources of information, we can gain a better understanding of the underlying processes and factors influencing the observed patterns. This can help in generating more meaningful and interpretable results, facilitating decision-making and domain expertise.
Overall, the benefits of multi-modal learning in remote sensing image analysis are numerous. From improved accuracy and robustness to better feature representation and interpretability, multi-modal learning holds great potential for advancing the field of GEOAI and unlocking new insights from remote sensing data.
Applications of Multi-Modal Learning in Remote Sensing Image Analysis
Multi-modal learning has found numerous applications in remote sensing image analysis. One of the key areas where it has shown great promise is land cover classification. By combining data from different modalities, such as optical imagery, LiDAR data, and Synthetic Aperture Radar (SAR) imagery, we can improve the accuracy and detail of land cover maps. This has important implications for various applications, including urban planning, environmental monitoring, and agricultural management.
Another application of multi-modal learning is object detection and recognition. By fusing information from different modalities, we can improve the detection and identification of objects of interest, such as buildings, roads, and vehicles. This can be particularly useful in urban areas, where the presence of different structures and objects can be accurately delineated and analyzed.
Multi-modal learning also plays a significant role in change detection and monitoring. By comparing data from different time points and modalities, we can identify and analyze changes in land cover, vegetation health, and other environmental factors. This can help in detecting and monitoring land degradation, deforestation, urban expansion, and other critical changes that impact the Earth's ecosystems.
These are just a few examples of the wide range of applications of multi-modal learning in remote sensing image analysis. With advancements in technology and the availability of diverse data sources, the potential for utilizing multi-modal learning approaches in GEOAI continues to expand, opening up new possibilities for understanding and managing the Earth's resources and environment.
Analysis of NIR Images and Multi-Modal Learning
Near-infrared (NIR) images play a crucial role in multi-modal learning for remote sensing image analysis. NIR light lies just beyond the visible spectrum and is not visible to the human eye. However, it carries valuable information about vegetation health, moisture content, and other surface features.
By integrating NIR images with other modalities, such as optical imagery or thermal data, we can improve the accuracy and detail of various analysis tasks. For example, in vegetation mapping, NIR images can help distinguish between different vegetation types based on their unique spectral signatures. This allows for more accurate classification and mapping of forests, crops, grasslands, and other types of vegetation.
NIR images also enable the estimation of various biophysical parameters, such as leaf area index, vegetation indices (e.g., NDVI), and canopy cover. These parameters provide valuable insights into plant growth, health, and productivity, and can aid in agricultural management, ecosystem monitoring, and climate change studies.
Furthermore, NIR images are particularly useful in applications where visual interpretation alone may be insufficient, such as in the detection of hidden objects or in challenging environmental conditions. By combining NIR images with other modalities, we can enhance the detection and analysis of objects and features that are not easily discernible in visible imagery alone.
In summary, the analysis of NIR images, in combination with multi-modal learning, offers a powerful approach to remote sensing image analysis. By leveraging the unique information carried by NIR light, we can improve the accuracy, detail, and interpretability of various analysis tasks, leading to better insights and decision-making in GEOAI.
Future of Multi-Modal Learning in GEOAI
The future of multi-modal learning in GEOAI looks promising, with several exciting developments on the horizon. With advancements in technology, we now have access to a wide range of data, including hyperspectral imagery, LiDAR data, SAR data, and social media feeds. Integrating these diverse sources of information, along with traditional optical imagery, can provide a more comprehensive and detailed understanding of the Earth's surface and its dynamics.
Deep Learning for remote sensing and GEOAI - DeepBlock.net