APPLICATIONS
이미지 분할
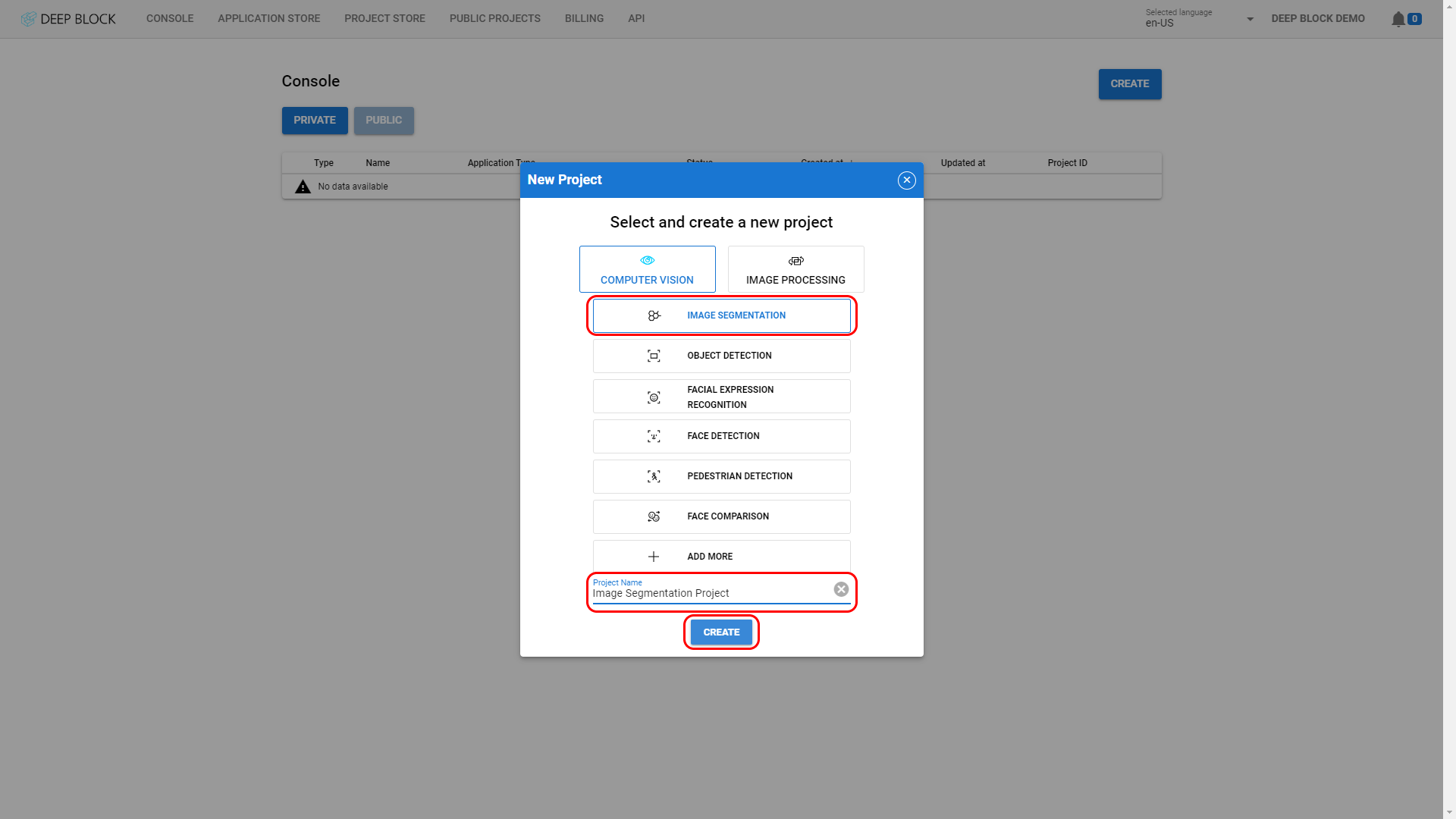
OVERVIEW
이미지 분할이란 무엇일까요?

이미지 분할은 이미지를 여러 세그먼트 또는 영역으로 분할하는 프로세스입니다. 각 세그먼트는 특정 개체나 개체의 일부에 해당합니다. 이미지 분할의 목표는 이미지에 존재하는 사물이나 구조물을 추출하여, 분석하는 것입니다.
Deep Block을 사용하면 해당 카테고리 또는 클래스 라벨 아래에서 다양한 객체를 분리할 수 있습니다. 이렇게 하면 다음과 같은 컴퓨터 비전 작업을 자동화할 수 있습니다.
- 객체 인식: 이미지를 구성 객체로 분할하면 각 객체를 개별적으로 인식하고 식별하는 것이 더 쉬워집니다.
- 형태학: 이미지 분할을 사용하면 크기, 모양, 색상 등 이미지의 개체나 영역에 대한 정보를 추출하여 정밀하게 분석할 수 있습니다.
- 이미지 분류: 분할을 통해 추출된 영역은 별도의 이미지가 될 수 있으며, 이미지 분류 작업의 입력으로 사용될 수 있습니다.
이를 통해 인스턴스(폴리곤)를 보다 정밀하게 분류하고, 보다 자세하게 분석할 수 있습니다. - 배경 빼기: 이미지 분할을 사용하여 이미지의 배경에서 개체를 분리할 수 있습니다.
- 측정: 분할 작업은 물체의 면적과 길이를 측정하고 기타 측정 작업에도 사용할 수 있습니다.

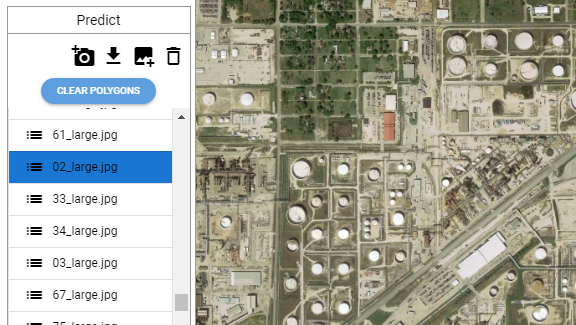
2 - Prediction Dataset
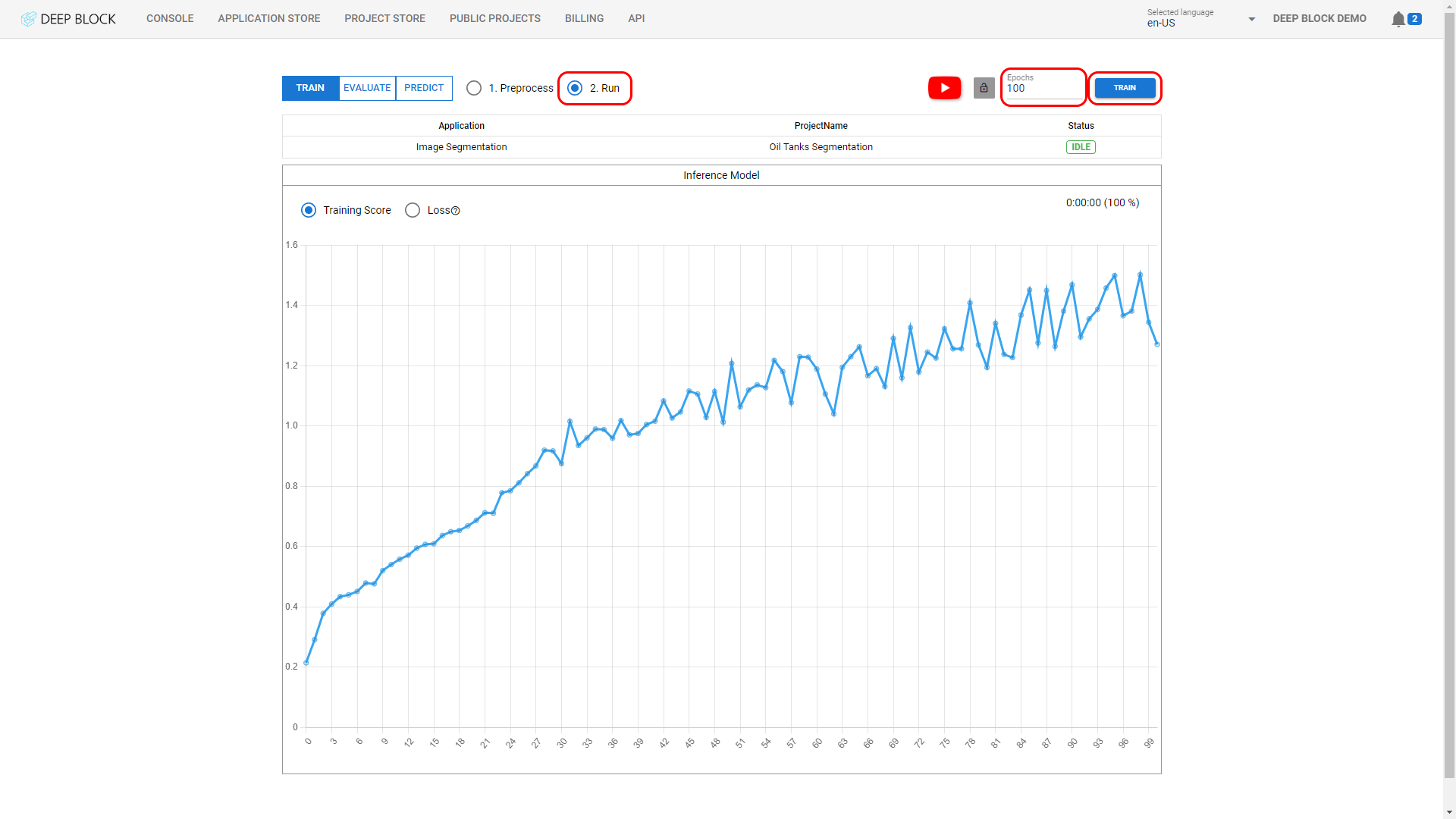
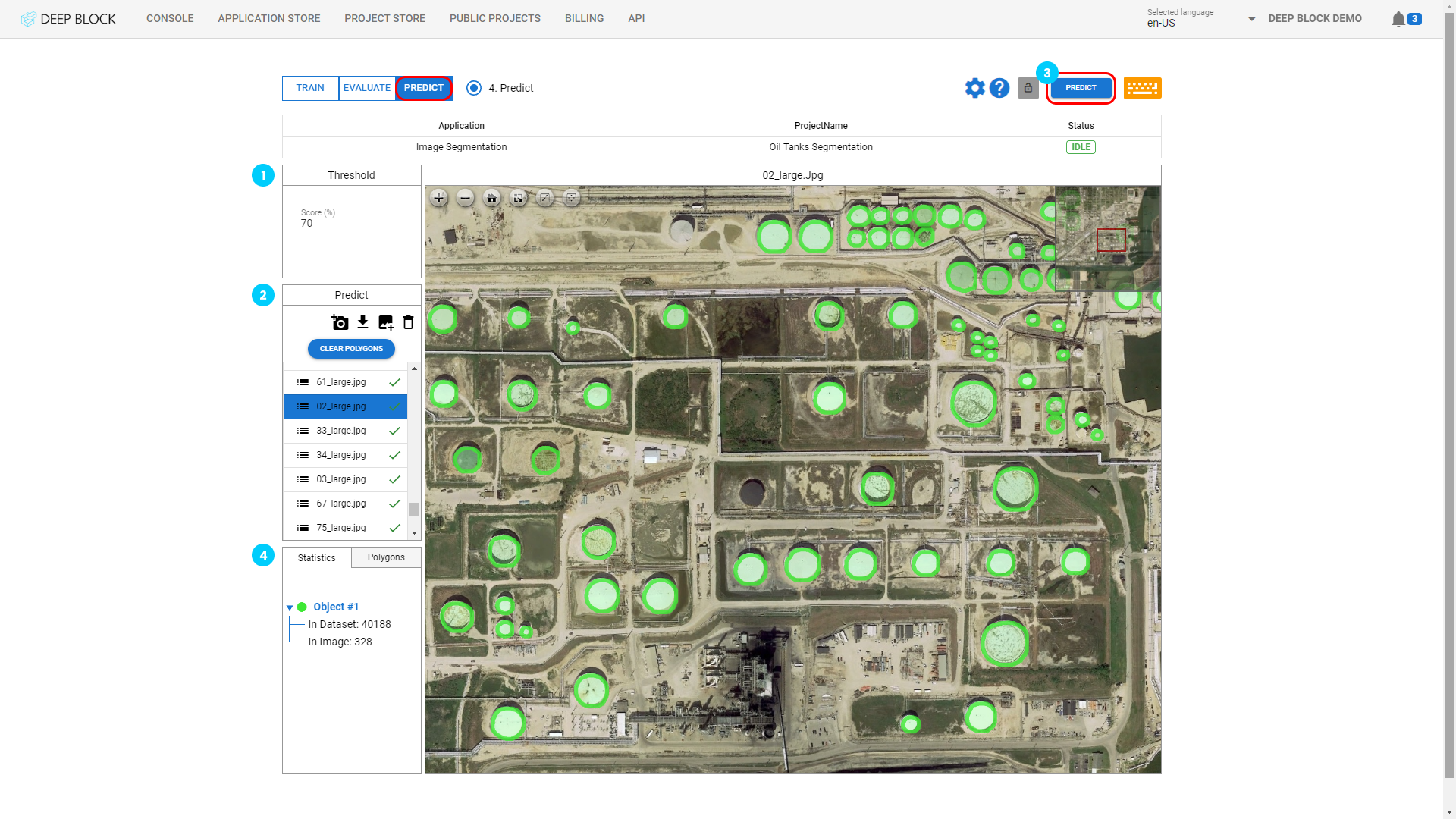
이제 모델을 훈련하고 평가했으므로 대규모 프로젝트를 통해 테스트해 볼 차례입니다. 이미지를 업로드하여 새로운 모델을 시험해 보세요.
- 웹캠을 통해 이미지를 추가하려면 "
 " 을 클릭하세요.
" 을 클릭하세요. - 추론 결과를 JSON파일로 다운로드하려면 "
 " 을 클릭하세요. (COCOJSON style or GEOJSON)
" 을 클릭하세요. (COCOJSON style or GEOJSON) - 사용하려는 이미지를 가져오려면 "
 " 을 클릭하세요.
" 을 클릭하세요. - 이미지를 선택한 후 "
 "를 클릭하면 이미지가 제거됩니다.
"를 클릭하면 이미지가 제거됩니다. - 예측이 이미 이루어진 경우 "CLEAR POLYGONS" 를 클릭하여 모든 폴리곤을 제거하세요.
지원되는 이미지 파일 형식은 png, webp jpg, geotiff, tiff, bmp 및 jp2(최대 파일 크기 10GB)입니다. 더 큰 파일을 업로드하려면 당사에 문의하세요.