
객체 탐지
Overview
객체 탐지(감지)란 무엇일까요?

객체 감지는 차량, 사람, 건물 등 이미지에서 관심 있는 객체를 식별하는 것을 목표로 하는 컴퓨터 비전 기술입니다. 객체 감지 모델은 이미지에 있는 객체의 위치와 ID를 나타내는 경계 상자 및 클래스 레이블 집합을 출력합니다. 또한 모델은 각 감지의 신뢰도 점수를 분석가에게 제공하여, 추측 결과가 얼마나 신뢰할만한 지 나타낼 수도 있습니다.
컴퓨터 비전에서 객체 감지가 사용되는 몇 가지 이유는 다음과 같습니다.
-
Automation: 객체 감지를 사용하면 감시 카메라 모니터링, 이미지에서 객체 감지 및 계산, 비디오에서 움직이는 객체 추적 등 수동 개입이 필요한 작업을 자동화할 수 있습니다.
-
Object Tracking: 객체 감지 모델을 사용하여 이미지의 객체를 추적할 수 있습니다. 일반적으로 객체 감지 모델은 객체 추적 알고리즘과 결합됩니다.
-
Object Counting: 개체 수를 세는 것은 의료 및 병리학 분야에서 매우 중요합니다. 객체 감지를 통해 찾아낸 객체의 개수는 Deep Block을 통해 쉽게 확인할 수 있습니다.
-
Context Awareness: 영상이나 복잡한 이미지를 이해하기 위해서는 이러한 이미지와 영상 속에 어디에 어떤 사물이 존재하는지 이해해야 합니다. 이를 위해 객체 감지 모델의 추론 결과는 다중 모달 ML 모델에 입력으로 다시 전달되어야 합니다.
-
Object Classification: 때때로 사람들은 이미지나 사물을 분류해야 할 때가 있습니다. 객체 감지는 객체를 감지하는 동시에 해당 객체가 어떤 카테고리에 속하는지 알려 주기 때문에 단순한 이미지 분류 모델보다 훨씬 유용합니다.
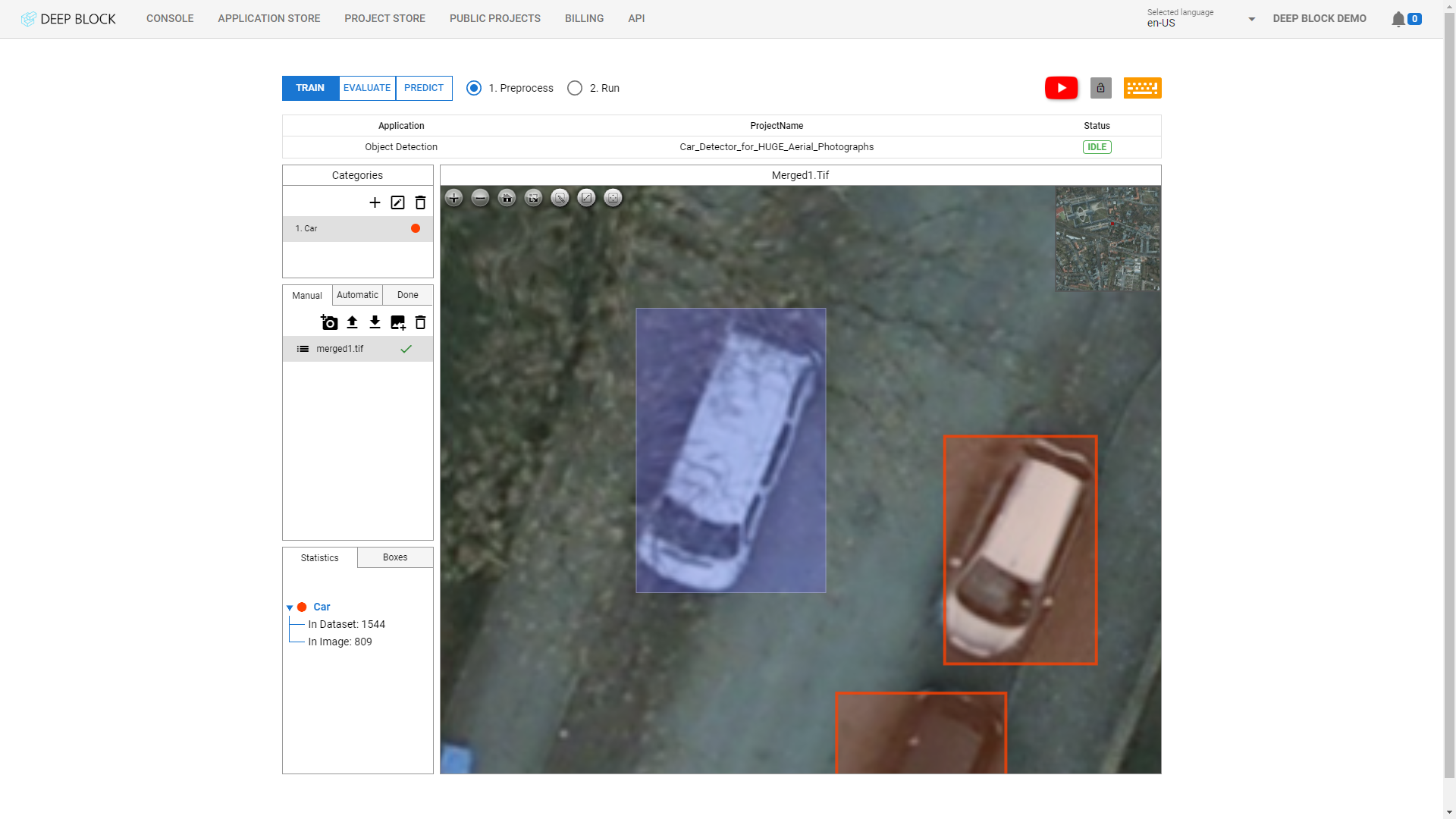
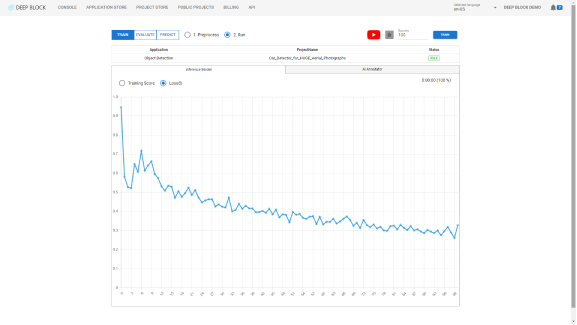
임계값 점수는 훈련된 기계 학습 모델의 감지 민감도를 나타냅니다.
임계값이 낮으면 기계 학습 모델은 거의 확신 없이 가능한 한 많은 개체를 찾으려고 시도합니다.
임계값 점수가 높으면 머신러닝 모델은 보장할 수 있는 분석 결과만 보여줍니다.
모델을 훈련시킨 후에는 먼저 임계값이 낮은 이미지를 분석하여 발견된 모든 개체의 신뢰도 점수를 확인한 다음 점차적으로 임계값 점수를 높여 최적의 임계값 점수를 결정하는 것이 좋습니다.
임계값 점수가 낮은 이미지를 먼저 분석한 후, 이미지의 추론 결과에 따른 각 경계 상자의 신뢰도 점수를 확인하고, 임계값을 위양성 사례의 신뢰도 점수보다 높게 높여 추론 정확도를 향상시킬 수 있습니다.
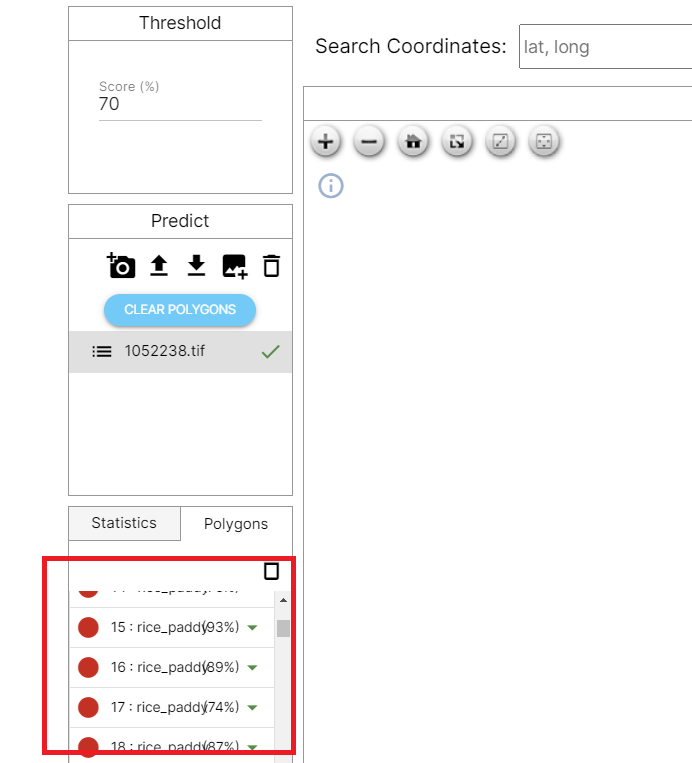
이를 통해 객체를 찾기 위한 최적의 임계값을 설정하는 동시에 위양성 사례를 줄일 수 있습니다.
- 임계값 점수(%) 필드에 적절한 값을 입력합니다.
물체 감지에서 임계값 선택은 감지 결과의 품질에 큰 영향을 미칠 수 있으므로 프로세스에서 중요한 단계입니다.
잘 훈련된 머신러닝 모델로 추론을 수행하면 높은 임계값 점수를 설정할 수 있으며, 이미지에 존재하는 모든 대상 개체가 정확하게 캡처됩니다.
- 웹캠을 통해 이미지를 추가하려면 "
 " 을 클릭하세요.
" 을 클릭하세요. - 사용하려는 이미지를 가져오려면"
 " 을 클릭하세요.
" 을 클릭하세요. - 이미지를 선택한 후 "
 " 를 클릭하면 이미지가 제거됩니다.
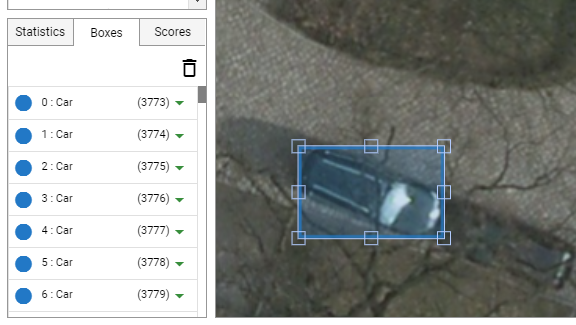
" 를 클릭하면 이미지가 제거됩니다. - 예측이 이미 이루어진 경우"CLEAR BOXES" 를 클릭하여 모든 바운딩 박스를 제거하세요.
지원되는 이미지 파일 형식은 png, jpg, svg, tiff, bmp, gif, geotiff 및 jp2(최대 파일 크기 10GB)입니다.
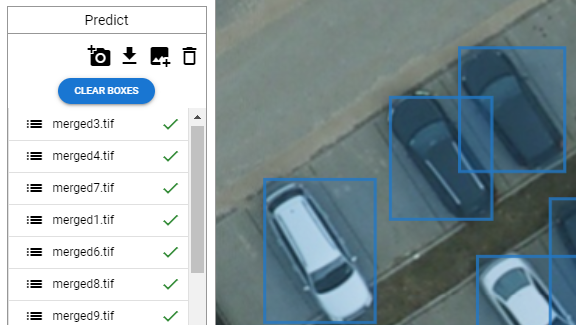
데이터 세트가 업로드되면 추론을 시작할 준비가 된 것입니다.
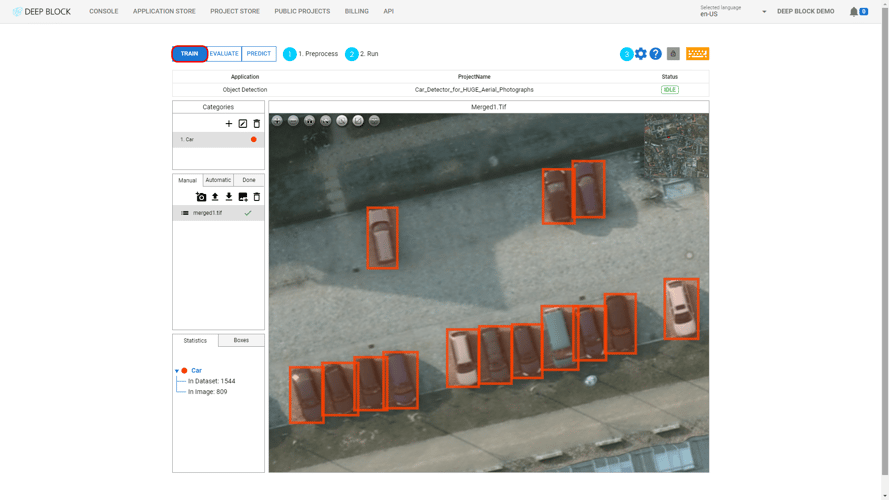
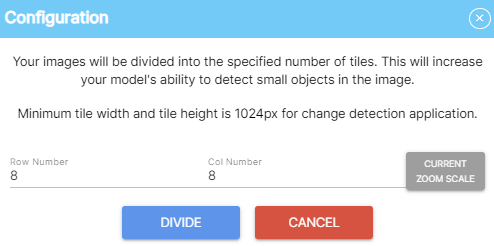
여기서 중요한 점은 대규모 이미지를 분석할 때에는 이미지를 여러 섹션으로 나누어 분석해야 한다는 점이다.
이에 대해서는 다음 글을 참고하시기 바랍니다.
드론 사진으로 훈련된 AI 모델을 사용하여 항공 사진 분할하기.
대규모 이미지 분석을 위한 Deep Block의 특허 알고리즘의 힘
- 먼저, 이미지 해상도가 크다면 이미지를 트레이닝할 때처럼 분할하세요.
이미지를 보다 정확하게 분석하려면 더 정확함 옵션을 사용하는 것이 좋습니다.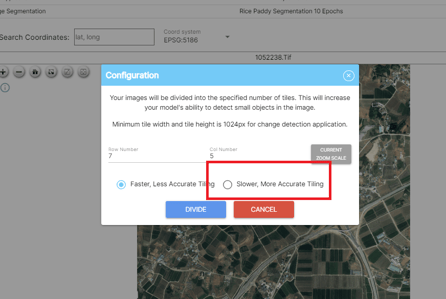
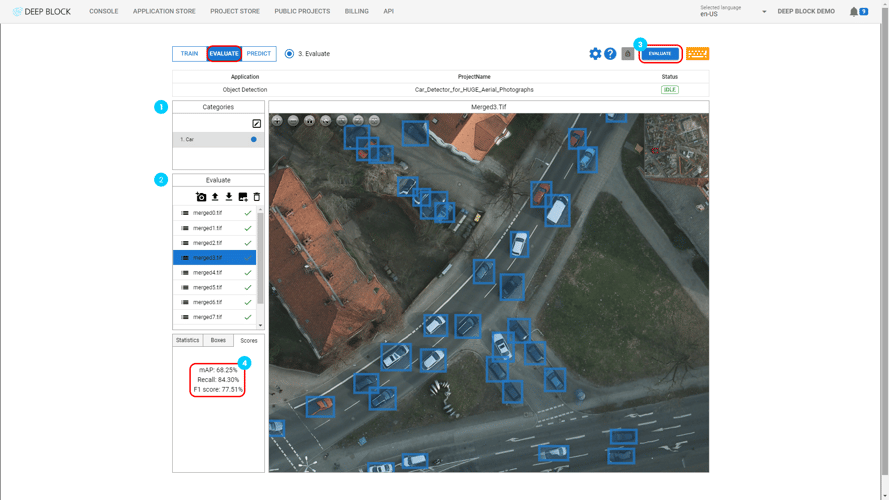
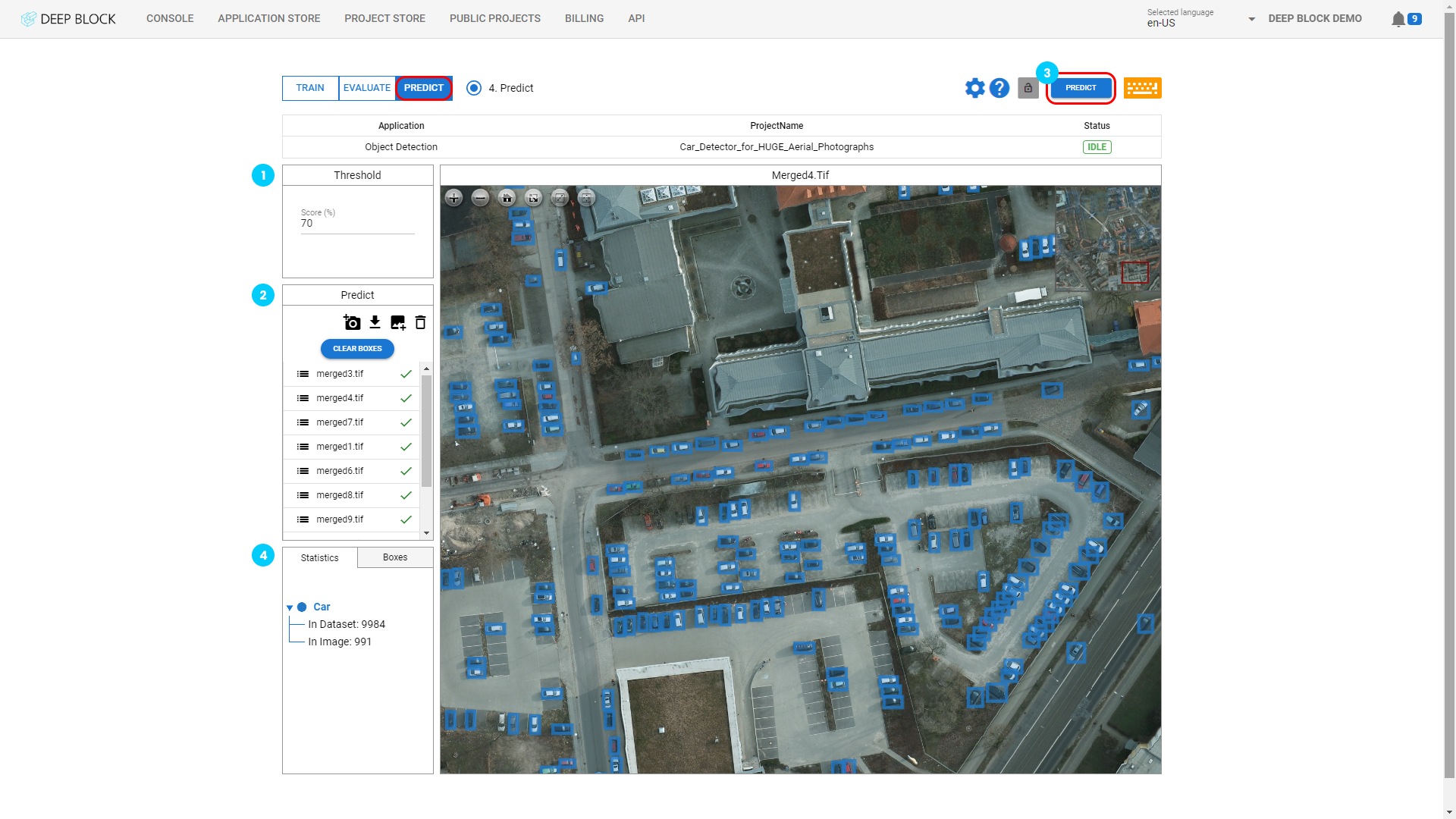
- 프로젝트 보기의 오른쪽 상단에 있는 "PREDICT"을 클릭하세요.
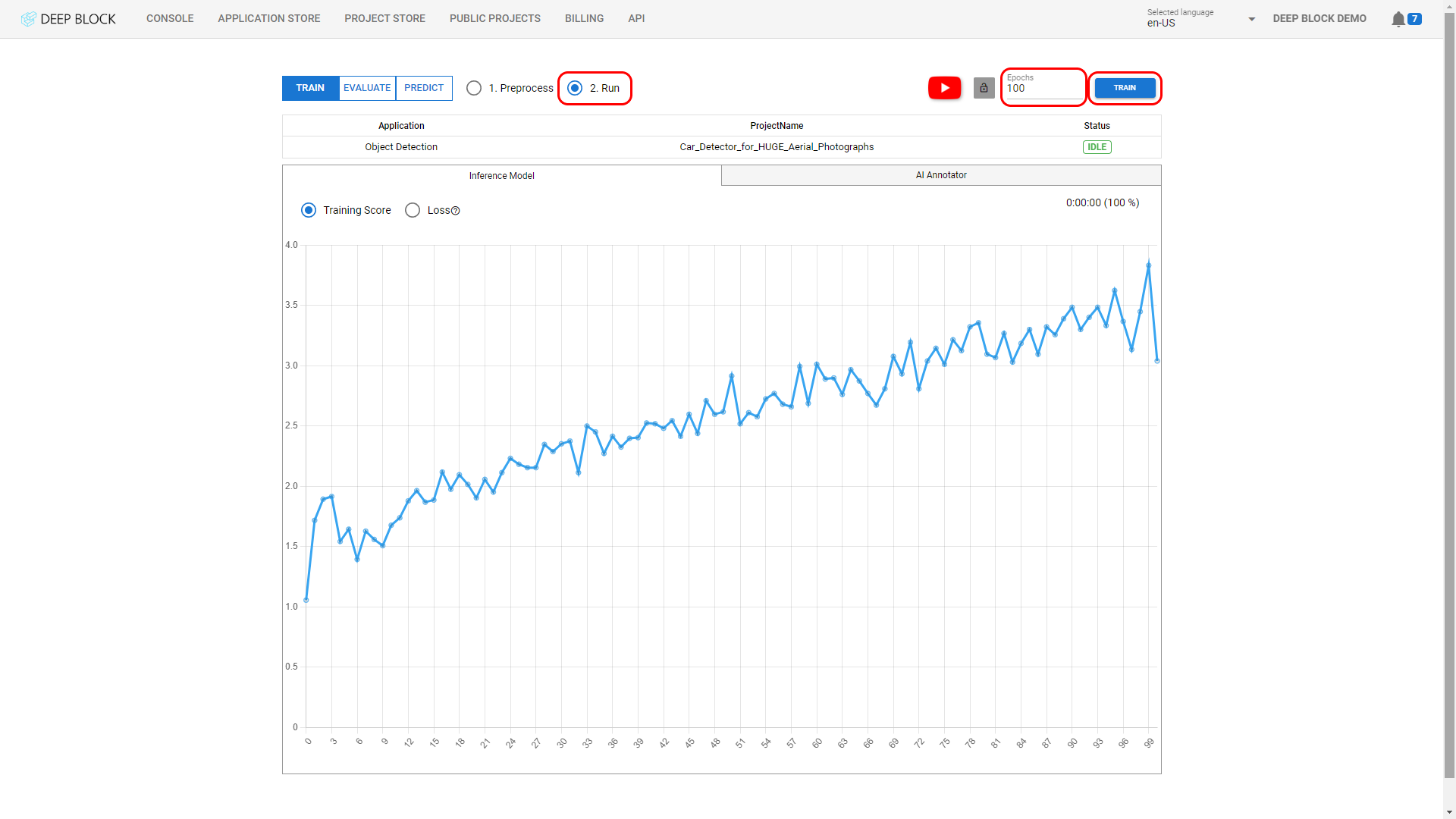
- 처리가 시작됩니다. 업로드된 이미지 수에 따라 이 프로세스는 몇 분 정도 걸릴 수 있습니다. "STOP"를 클릭하면 언제든지 중지할 수 있습니다.
처리 상태가 "IDLE"로 돌아올 때까지 기다리십시오.